Person identification is the process of identifying or verifying a person from a digital image or video frame from a video source. With increasing number of surveillance cameras installed in public area and automatic identification widely used in industry as well as government especially for law enforcement and security purpose, it is essential to find more accurate and efficient algorithms to this problem. In our project, we are going to explore new approaches for person identification with face information and body information.
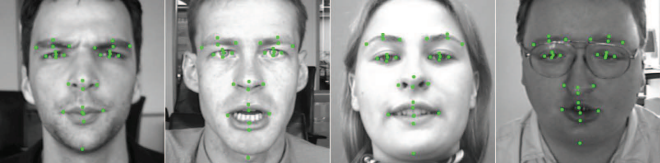
For face-based person identification, we capture each individual's face images, and identify a person through face recognition. Multiple methods have been developed for face recognition, such as principle component analysis (PCA) using eigenfaces, linear discriminate analysis. Such a problem becomes challenging when face images are taken with extreme poses, lightings, expressions, and occlusions. Therefore, it is often necessary to do face alignment before recognition with the help of face key points such as eye corners, mouth corners, and nose tip. The performance of a face recognition system is to a large degree dependent on the accuracy of face keypoint detection. Consequently, it is meaning full to find better methods for face keypoint detection, which is also our focus in order to improve the accuracy of face recognition.
For many applications such as person tracking or person retrieval, it is not necessary to uniquely identify a person. It often suffices to determine previous or future occurrences of the same person in other images or videos. It can find applications in modern surveillance systems, either for online tracking of an individual over a network of cameras or offline retrieval of all videos containing a person of interest.

This problem is more challenging because when matching images of the same person captured with non-overlapping cameras, there may exist huge discrepancies in terms of human poses, illumination, camera views and photometric settings, and so on. In addition, the lack of sufficient resolution in surveillance cameras makes it infeasible to identify a person using face verification. In this case, a total different method from that for face recognition is needed.
This project aims to explore new approaches for face-based and body-based person identification, and improve its accuracy. In particularly, for face-based person identification, our focus is on developing new methods for more accurate face keypoints detection. Based on the new approach, we expect to develop an integrated system for person identification, covering the process from photo taking, image cropping, feature extraction, to identification.
We have noticed that highly discriminative feature descriptors such as local binary patterns(LBP) and color historgrams are critical to achieve high accuracy, and these feature descriptors are often of high dimensional. High dimensional features are necessary to high performance, but they also introduce the extra problems like overfitting and large amount of computations. Therefore, dimension reduction methods such as PCA and CCA are often applied to aggressively reduce the dimension of feature descriptors. However, in this process subtle but highly discriminative information may be overlooked, especially when many different types of features are combined together, which decreases the discriminative power of the new features after dimension reduction.
Considering this, our solution is inspired by the behavior of human witnesses. Imagine multiple witnesses work together in an effort to reenact a past event and draw conclusions. Suppose none of them saw the complete event. Each of them would try to recall the partial evidences he/she has and provide opinions accordingly. At the end, a much more complete understanding of the event as well as some conclusions can be reached by piecing together the partial evidences and opinions from individual witnesses. In the same spirit, we hope to propose a method that trains a group of witness functions, each of which is only exposed to a random subset of the input features. Each witness function produces an opinion according to the partial features it has. We will aslo introduce a weighted fusion scheme to combine the opinions of multiple witness functions together.
Supervisor: Prof. Yizhou Yu
Student: Bi Sai