INSPIRATION
INSPIRATION
Over the years, people have been trying to exploit the abilities of a computer to create a better world. One of such abilities is to make decision as if human do. A way to show the capability of a computer making good decision is by playing board games as it involves the evaluation of the current board settings and selecting the next best moves constantly throughout the game. It is also a good way to evaluate how good a computer can perform when compared with human.
 COMPUTER BOARD GAME
COMPUTER BOARD GAME
Traditionally, a computer plays a board game by searching through the game tree - a tree containing all the possible moves with the corresponding weights, which indicate how likely one can win the game with those moves. The values of the weights are being assigned according to an evaluation function.
Due to the limited storage and the complexity of the game search tree, the computer has to prune the branches with less weight for decision-making.
 PROJECT FORMULATION
PROJECT FORMULATION
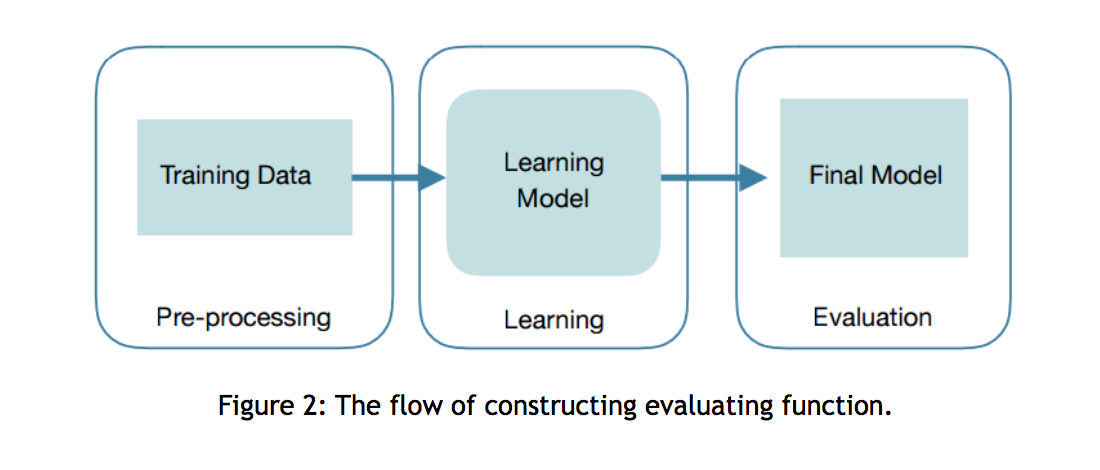
Inspired by the human brain, neural network is a way of information processing. Several layers of notes in the neural network are connected together and change as the system is trained. A large amount of training data are used to fine-tune the connections during the training process so that the network can produce a specific output corresponds to the given input. A deep learning neural network is a network with many layers. This deep learning neural network can help increase the accuracy of the results generated by the evaluation function throughout a series of learning processes, and hence, can help the computer make better decision of which branches to prune when searching for the next best move.
This project aims to demonstrate how powerful deep learning neural network can be for game-playing. The game Othello is chosen as the technique of deep learning neural network can be applied this game. Meanwhile, the size and the complexity of this game is suitable for a one-year long project with limited resources.
 OBJECTIVES
OBJECTIVES
The objective of this project to develop a computer Othello program with the following attributes:
- The game board configuration being the size of 8x8
- A winning rate of 50% when playing against a moderate (computer) opponent
- A winning rate of 35% when playing against a strong (computer) opponent
- A user-friendly UI for easy playing
While the ultimate outcome is to deliver the above program, the key of this project is to allow the evaluation function of the program being constructed by the program itself without human logic.