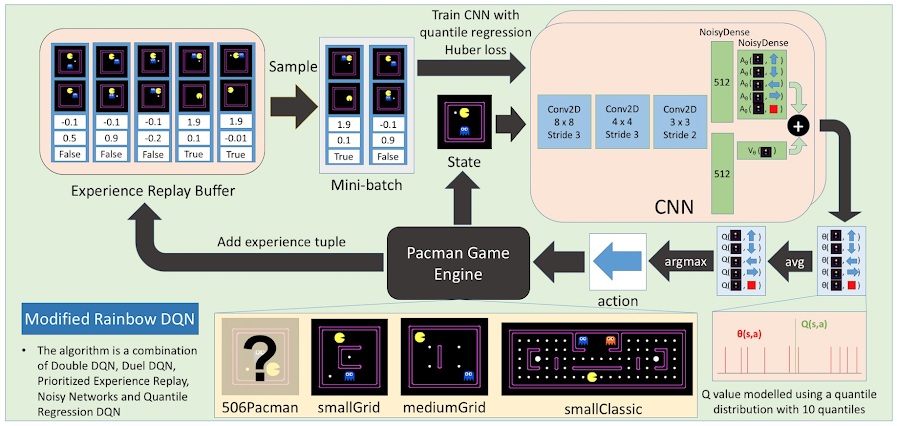
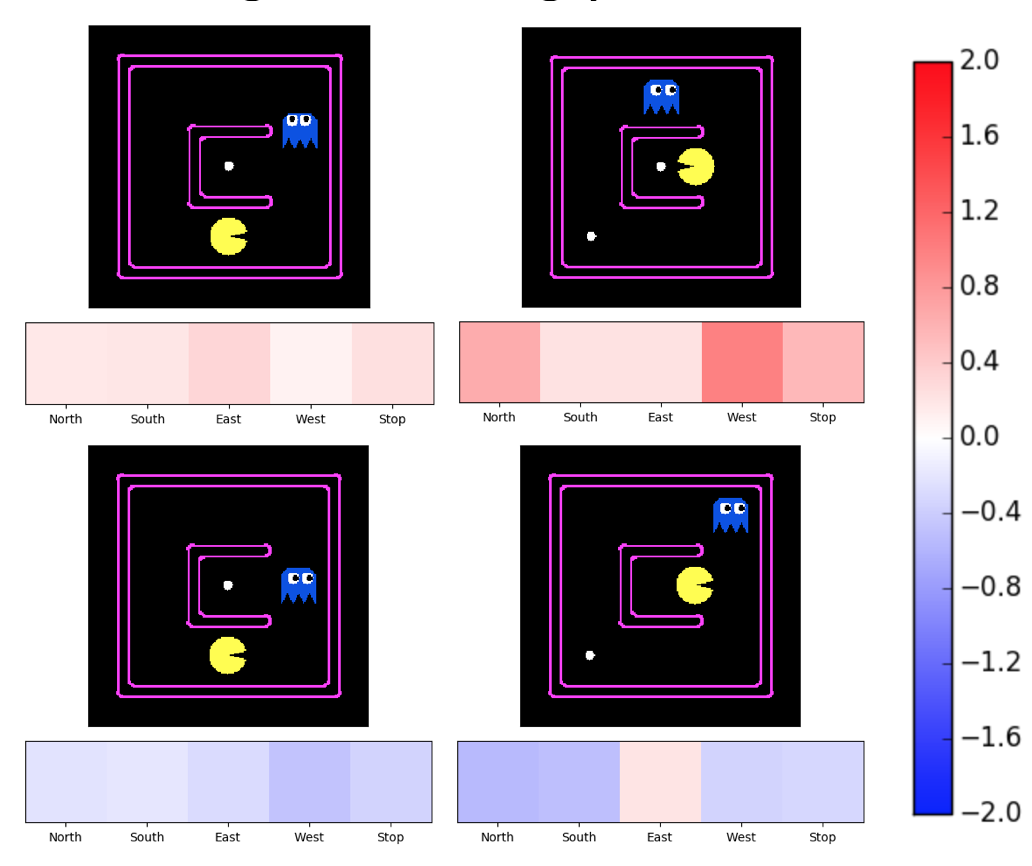
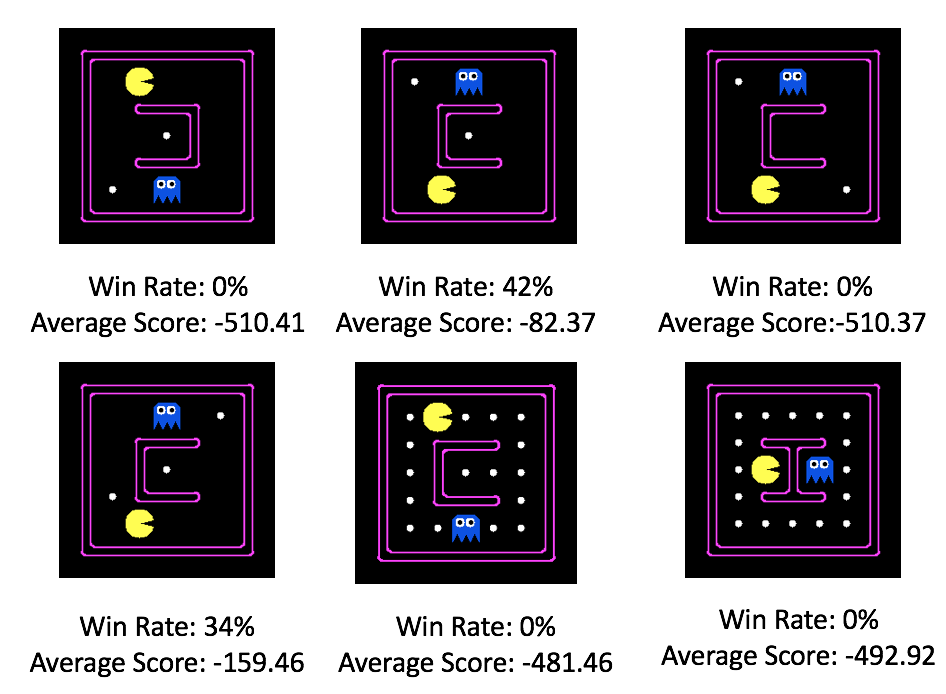
About
The project's main objective is to use reinforcement learning and deep learning in order to play computer games, specifically Pacman. The project will be broadly divided into two stages. Specifically, the first stage involves exploration of various reinforcement algorithms and neural network architectures by using Pacman as a benchmark. The second stage would then involve improving the algorithm and subsequently testing it on Pacman maps.