Background
Artificial Intelligence has become one of the topics that are discussed and studied most by the public and researchers in recent years. AlphaGo, with credits to the machine learning research team DeepMind, is probably considered as the most groundbreaking application of AI which stunned people, even those without related knowledge, by the triumph over the top human Go players. In fact, AI has already become a crucial element in different sectors in our societies, for example, smart cars, chat bots for customer service, and here, trading which could possibly be the most profitable application. Therefore, this project aims at harnessing the power of AI in stock trading.

Objectives
1. Explore AI algorithms with different premises.
2. Study factors affecting performance.
3. Make improvements to base models.
4. Aim at producing a profitable model!
Models
In this project, 3 types of algorithms have been studied which have different theories and mechanisms as their foundations. They are namely:
1. Recurrent Neural Network (RNN)
2. Reinforcement Learning (RL)
3. Deep Reinforcement Leanring (DRL)



Methodology
Recurrent Neural Network
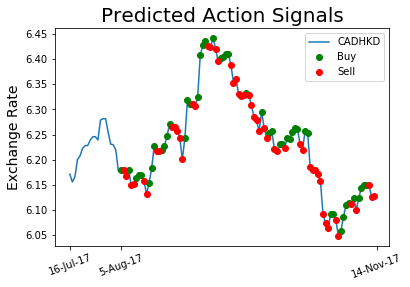
In contrast to other deep neural networks with layers connected to layers, RNNs take a recursive structure so output is at the same time used as input of next time step. Considering this recursive strucutre, one may conjecture that the sequence of input may show implications on the learning process. In fact, RNNs are usually used for time series prediction which is also tested in this project. Trade actions are then determined with a precise price preiction.
The figure below illustrates the recursive (left) and unfolded (right) representation in graphical form.

Methodology
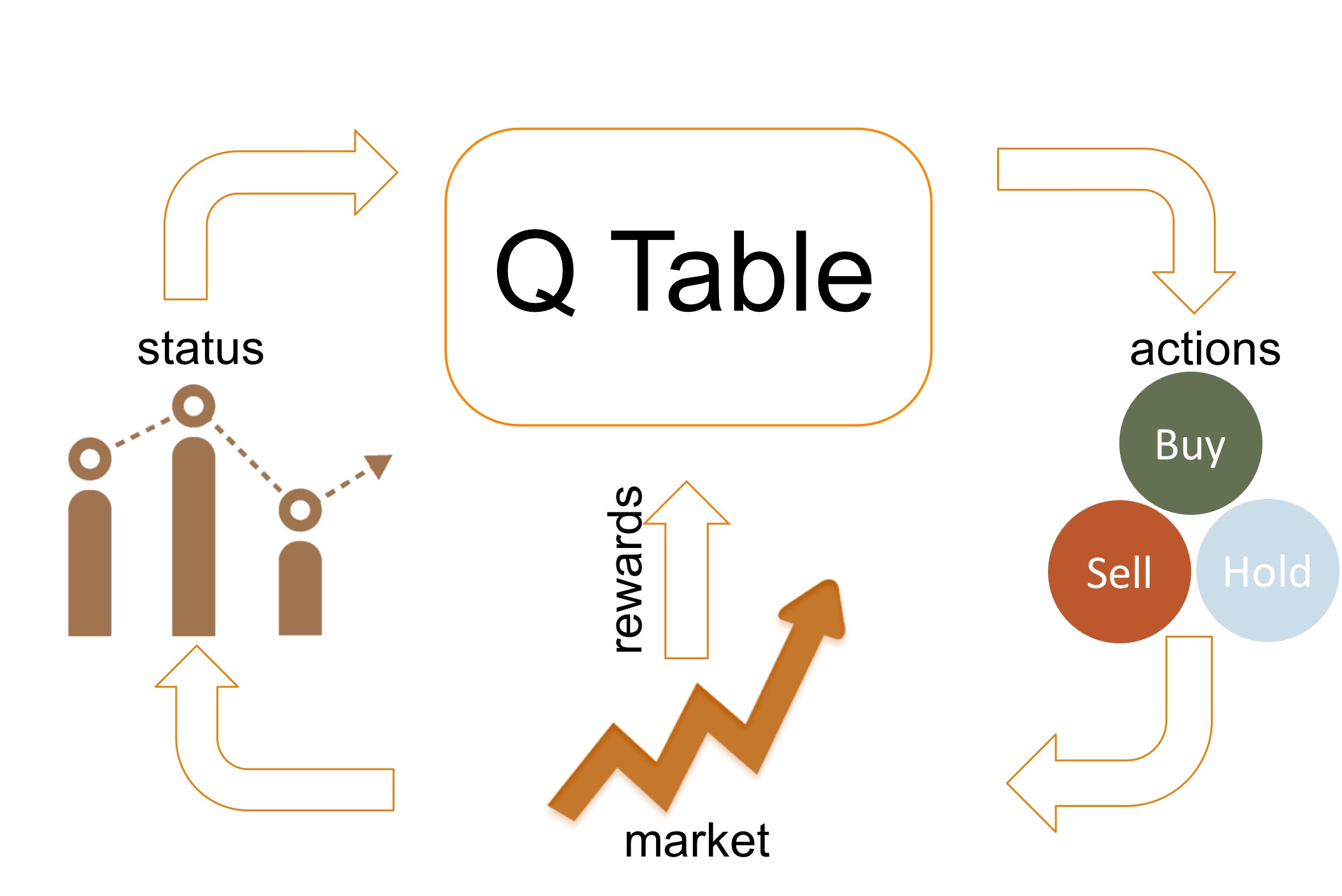
Reinforcement Learning
Reinforcements learn the trading strategy in a "Trial and Error" mode. The stock market is first described by a state space. Reinforcement models then keep taking trading actions at different states, and observe the rewards returned by the market. After iterations of failures and successes, RL devises a strategy maximizing the profits.
Q Learing is the learning algorithm studied in this project. With Q Learing, a Q Table is used akin to a trading policy, which stores Q values that tell one the best action on a given state.
The figure below describes the flow of learning with Q Learning.
Methodology
Deep Reinforcement Learning
DRL takes a step further by capturing the state space with a deep neural network. With the traditional Q Table, discritization of state space seems to be inevitable, which may cause a loss in accuracy in modelling the complicated stock market. With a deep neural network, the state space is allowed to be real-valued, and give a more complete picture of the market.
Double Deep Q Network
DDQN was first adopted by DeepMind on playing Atari games (link) which aims at improving RL by stablizing the learning through the use of 2 DQNs instead of 1 only. DDQN was shown to provide (1) better performance than RL and even human players and (2) capability for various of gamaes based on only screen display. This project attempts to apply this groundbreaking technique to the field of stock trading, where much fewer researches serve similar purpose, as compared to those with RNN and RL.
Experience Replay
DDQN works hand in hand with another technique named as Experience Replay. In traditional reinforcements, update of Q values or policies is done for each state-action-reward pair is observed. With Experience Replay, state-action-reward-next_state pairs are first memorized as experiences in the training phase. Later, batches of experiences are sampled out and used to update the target of learning. This is the mechanism adopted by DeepMind to minimize the unstablility of RL.
The figure below describes the flow of learning with DDQN.
Test Results
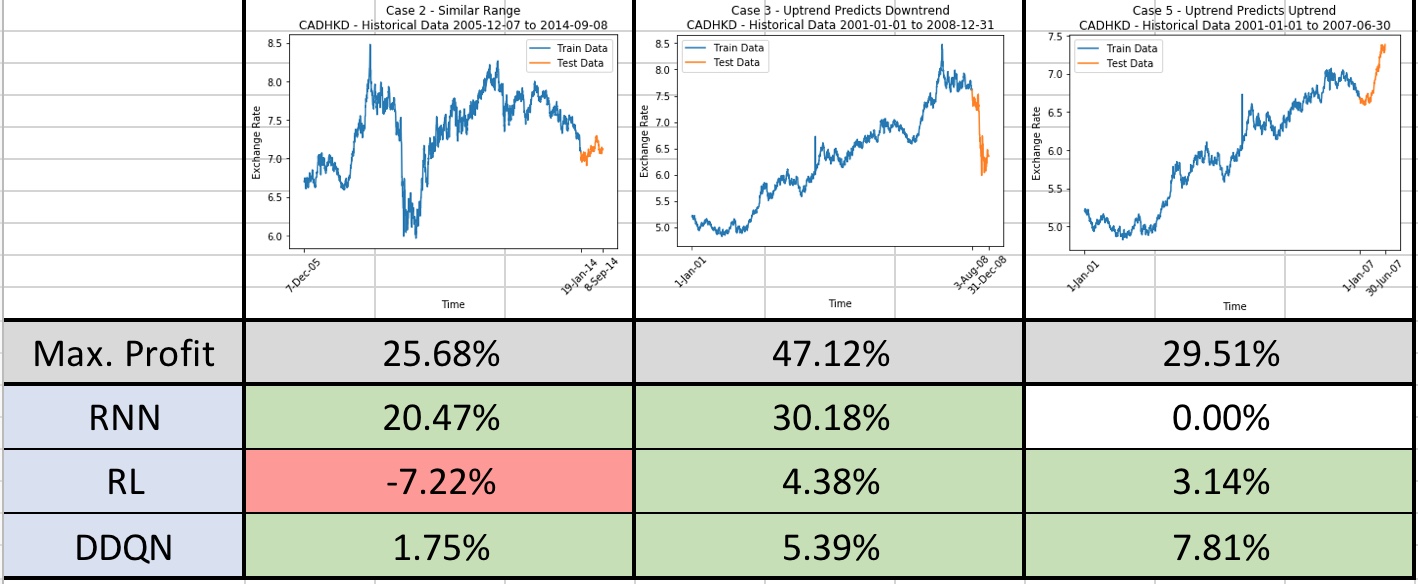
After extensive configurations, experiments and improvements, models supported by the 3 algorithms have been implemented and tested with real stock data. The following shows performances of the models agianst CADHKD in different time periods, which are chosen to simulate different situations in real-life trading. For each line chart, the blue line represents the training data while the orange line represents the test data. The theoretical maximum possible profits are produced by making correct actions all the time (without making losses).
Simplicity is Beauty
It is noted that trading by predicting the future price levels has been the most effective and profitable way among different situations as shown above. In most of the cases, RNN model was successful in making profits close to the maximum possible profit in each case. It is even remarkable that for the second case (middle) profit is retained even for the sudden drop of prices in test data.
Stablizing Effect
RL models may not be as excellent and making as much profits as the price-predictive RNN models do. However, DDQN successfully stablizes the performances. Although not earning as much as RNN models, DDQN consistently generating positive profits.
Report
The above shows results on the most representative models and experiments. Many other models have been implemented and experimented which are documented in a more detailed report.
AI Application on Algorithmic Trading - FYP Complete Report

About the Project
This project serves as the final year project as required in the curriculum of BEng(CompSc) in HKU. The following gives the information about this project:
Project Title: AI Application on Algorithmic Trading
Supervisor: Dr. S.M. Yiu
Student: Chan Wing Hei
Acknowledgement
I would like to present my earnest gratitude to my supervisor Dr. S.M. Yiu, who granted me the valuable opportunity of working on this project about Artificial Intelligence, which is one of research fields that are showing great potential in this generation. Meanwhile, Dr. Yiu has given me his precious opinions which gave me directions to work on this project.