
|
ZHANG Qiping, qpzhang (at) cs.hku.hk
|
|
Objectives |
|
|
This project aims to design an efficient approach for semantic video segmentation, which allows researchers to accurately segment all objects in the image scenes of consecutive video frames and classify them based on their concept/meaning. The intermediate goal for this project, is to apply deep learning techniques to perform semantic segmentation of videos captured from in-car cameras based on the state-of-art models and algorithms. Specifically, we will first select a suitable semantic video segmentation dataset to perform training and testing of machine learning models in our further work, and then investigate the high-performance approaches recently developed by other researchers. An evaluation will be made on these models in terms of their efficiency and accuracy, and comparison will be made to check the difference made by their distinctive models, algorithms and system architectures. In this way, advantages and deficiencies of the existing methods could be exposed and verified, and possible ways of improvement and modification could be discovered for further experiment. The ultimate goal for this project, is to design and train a deep neural network that can produce temporally coherent semantic segmentation of a video. Our desired model for semantic video segmentation should also be able to maintain a consistency along time-dimension, besides the spatial correctness and meaningfulness required by object classification in a single 2D image. In other words, a qualified and ideal model for semantic video segmentation should not only correctly classify the pixels of each image frame into real-world objects, but the classification of nearby frames should not undergo an obvious fluctuation. The model to be constructed in this project is expected to outperform the previous approaches in at least one aspect, for example, leading to less computational power consumption or higher segmentation accuracy. |
|
|
Background |
|
|
As one of the most traditional and basic fields in computer vision research, semantic segmentation intuitively refers to the process of assigning a class label (e.g., road, tree, sky, pedestrian, car, ...) to each pixel of an image. Great importance is continuously attached to this area since it usually performs as the substantial preprocessing stage in many vision tasks, such as scene parsing and understanding. Generally, semantic segmentation consists of three basic steps: object detection, shape recognition and classification, each of which contains space of further efficiency improvements. However, when the problem domain generalizes to video instead of a single image, researchers are confronted with more challenges: in brief, as a concatenation of consecutive frames, video segmentation is a more difficult problem because consistency should be maintained between a certain number of neighborhood images, i.e. the nearby frames should not contain greatly distinctive classification patterns with each other. This inherent characteristic has contributed to the obstacles in the design of semantic video segmentation algorithms. |
|

Autonomous driving |
Medical imaging analysis |
|
Methodology |



|
|
This project will use the mainstream machine learning platform PyTorch developed by Facebook's AI research group to carry out model training and evaluation experiments. Because of PyTorch's flexibility in modifying neural networks architecture, concise code for manipulating training strategy and popularity among the machine learning community, it allows us to run existing examples proposed by other researchers which are mainly open-source PyTorch projects. In this way, we can identify key drawbacks of semantic segmentation and make improvements to tackle some particular obstacles. Besides PyTorch, some open source computer vision libraries like OpenCV will be leveraged for the purpose of processing dataset. These libraries provide standard and performance-optimized codes for commonly used features, for example, reading and transforming images. In terms of hardware, this project will take the advantages of GPUs for training models. GPUs pipelines work parallelly and thus make the training process efficient enough for complex model architecture and large dataset. Meanwhile, due to the inherent features of these deep learning framework and the computer vision library, Python and C++ will be the major programming languages used in this project, where Linux will become our main developing environment accordingly. The GPU server (1080 Ti/Titan) provided by supervisor will give the necessary computational power needed in the training/testing of neural networks, and other data processing tools, such as Matlab, will also be utilized based on actual requirement. |
|
|
Deliverables |
|
|
Dataset is a crucial part of a machine learning project as machine learning is mainly about learning the patterns of a given dataset. However, this project will not include collecting its own dataset, but employ existing open source benchmark dataset. One reason is that collecting data and annotating the ground truth require considerable human labor work, which is hard for a final year project. Another reason is that, open source datasets are well organized and accurately annotated. Many research teams work on them and thus they can provide benchmarks for evaluating model performance. As machine learning is data-oriented, the final output model will only work with similar types of data as the training data. For example, if we train the model to segment a road condition video, it will not work if the input videos are of other scenarios such as a medical detection video inside a human body. Thus, this project will avoid emphasizing on the final output of the model, but focusing on the techniques our model uses to manipulate the video and the network architecture of the model. Particularly, this project will try to find techniques to achieve low-latency and at the same time maintain satisfactory accuracy level. These innovations will serve for general semantic segmentation problems and thus will be a highlight of this project. |
|

|
|
|
Sample input frames of CamVid Dataset & ground-truth
|
|
|
Schedule |
|
|
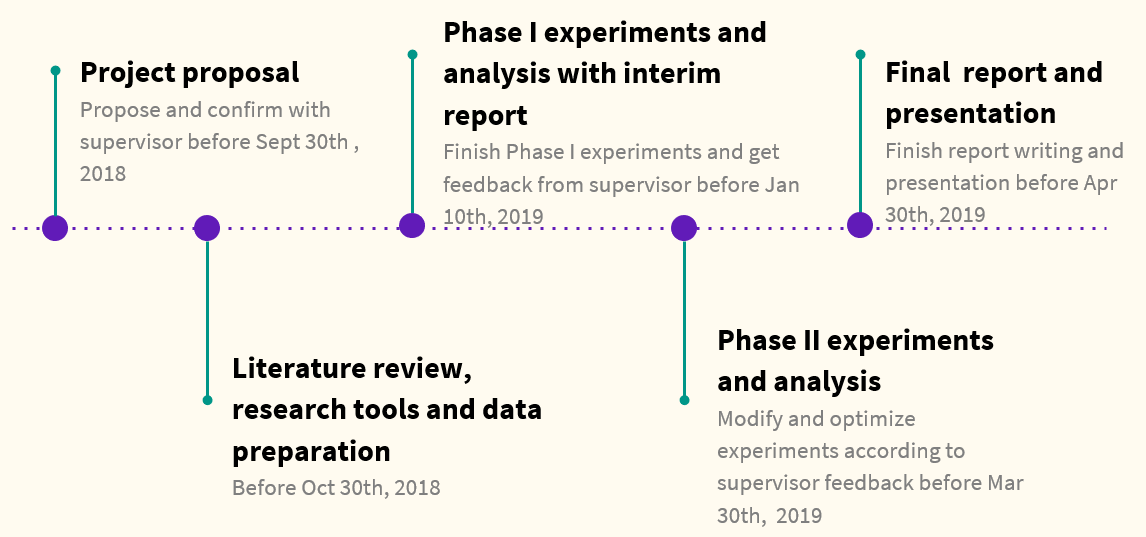
This project is cooperated by Zhang Qiping and Cai Jinyu. Both will participate in brainstorming and carrying out experiments and will share a fair part of this project. However, Cai will focus on the implementation of ideas as he is familiar with the tools. Zhang will focus on setting up different experiment strategies as he has more research experience. As is shown by the figure below, this project starts in early September, with the project plan proposed by the 30th of September, 2018. Then one month will be spent on literature review, research tools and data preparation. And between November 1st, 2018 and March 30th, 2019, there will be two phases of experiments and analysis, each taking around two and a half months. Phase II experiments will be modifying and optimizing our models based on the progress and results of phase I experiments and feedback from the supervisor. An interim report will be submitted after finishing phase I experiments. And after finishing phase II experiments, one month will be left for finalizing the final report and presentation on April 30th, 2019. |
|
|
|
|
Preliminary Timeline of Project
|
|