
Neural Style Transfer: A Review
Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, Yizhou Yu, and Mingli SongIEEE Transactions on Visualizationa and Computer Graphics, Vol 26, No 11, 2020, [BibTex]
The seminal work of Gatys et al. demonstrated the power of Convolutional Neural Networks (CNNs) in creating artistic imagery by separating and recombining image content and style. This process of using CNNs to render a content image in different styles is referred to as Neural Style Transfer (NST). Since then, NST has become a trending topic both in academic literature and industrial applications. It is receiving increasing attention and a variety of approaches are proposed to either improve or extend the original NST algorithm. In this paper, we aim to provide a comprehensive overview of the current progress towards NST. We first propose a taxonomy of current algorithms in the field of NST. Then, we present several evaluation methods and compare different NST algorithms both qualitatively and quantitatively. The review concludes with a discussion of various applications of NST and open problems for future research. A list of papers discussed in this review, corresponding codes, pre-trained models and more comparison results are publicly available at: https://osf.io/f8tu4/ .

Self-Enhanced Convolutional Network for Facial Video Hallucination
Chaowei Fang, Guanbin Li, Xiaoguang Han, and Yizhou YuIEEE Transactions on Image Processing, Vol 29, 2020
As a domain-specific super-resolution problem, facial image hallucination has enjoyed a series of breakthroughs thanks to the advances of deep convolutional neural networks. However, the direct migration of existing methods to video is still difficult to achieve good performance due to its lack of alignment and consistency modelling in temporal domain. Taking advantage of high inter-frame dependency in videos, we propose a self-enhanced convolutional network for facial video hallucination. It is implemented by making full usage of preceding super-resolved frames and a temporal window of adjacent low-resolution frames. Specifically, the algorithm first obtains the initial high-resolution inference of each frame by taking into consideration a sequence of consecutive low-resolution inputs through temporal consistency modelling. It further recurrently exploits the reconstructed results and intermediate features of a sequence of preceding frames to improve the initial super-resolution of the current frame by modelling the coherence of structural facial features across frames. Quantitative and qualitative evaluations demonstrate the superiority of the proposed algorithm against state-of-theart methods. Moreover, our algorithm also achieves excellent performance in the task of general video super-resolution in a single-shot setting.

A Benchmark for Edge-Preserving Image Smoothing
Feida Zhu, Zhetong Liang, Xixi Jia, Lei Zhang, and Yizhou YuIEEE Transactions on Image Processing, Vol 28, No 7, 2019, [BibTex] (Dataset and Model Download)
Edge-preserving image smoothing is an important step for many low-level vision problems. Though many algorithms have been proposed, there are several difficulties hindering its further development. First, most existing algorithms cannot perform well on a wide range of image contents using a single parameter setting. Second, the performance evaluation of edge-preserving image smoothing remains subjective, and there lacks a widely accepted datasets to objectively compare the different algorithms. To address these issues and further advance the state of the art, in this work we propose a benchmark for edge-preserving image smoothing. This benchmark includes an image dataset with groundtruth image smoothing results as well as baseline algorithms that can generate competitive edgepreserving smoothing results for a wide range of image contents. The established dataset contains 500 training and testing images with a number of representative visual object categories, while the baseline methods in our benchmark are built upon representative deep convolutional network architectures, on top of which we design novel loss functions well suited for edge-preserving image smoothing. The trained deep networks run faster than most stateof-the-art smoothing algorithms with leading smoothing results both qualitatively and quantitatively. The benchmark is publicly available.

Image Super-Resolution via Deterministic-Stochastic Synthesis and Local Statistical Rectification
Weifeng Ge*, Bingchen Gong*, and Yizhou YuSIGGRAPH Asia 2018 (ACM Transactions on Graphics, Vol 37, No 6, 2018), [BibTex] (PDF, Supplemental Materials)
Single image superresolution has been a popular research topic in the last two decades and has recently received a new wave of interest due to deep neural networks. In this paper, we approach this problem from a different perspective. With respect to a downsampled low resolution image, we model a high resolution image as a combination of two components, a deterministic component and a stochastic component. The deterministic component can be recovered from the low-frequency signals in the downsampled image. The stochastic component, on the other hand, contains the signals that have little correlation with the low resolution image. We adopt two complementary methods for generating these two components. While generative adversarial networks are used for the stochastic component, deterministic component reconstruction is formulated as a regression problem solved using deep neural networks. Since the deterministic component exhibits clearer local orientations, we design novel loss functions tailored for such properties for training the deep regression network. These two methods are first applied to the entire input image to produce two distinct high-resolution images. Afterwards, these two images are fused together using another deep neural network that also performs local statistical rectification, which tries to make the local statistics of the fused image match the same local statistics of the groundtruth image. Quantitative results and a user study indicate that the proposed method outperforms existing state-of-the-art algorithms with a clear margin.

• Stroke Controllable Fast Style Transfer with Adaptive Receptive Fields
Yongcheng Jing, Yang Liu, Yezhou Yang, Zunlei Feng, Yizhou Yu, Dacheng Tao, and Mingli SongEuropean Conference on Computer Vision (ECCV), 2018, PDF.
Fast Style Transfer methods have been recently proposed to transfer a photograph to an artistic style in real time. This task involves controlling the stroke size in the stylized results, which remains an open challenge. In this paper, we present a stroke controllable style transfer network that can achieve continuous and spatial stroke size control. By analyzing the factors that influence the stroke size, we propose to explicitly account for the receptive field and the style image scales. We propose a StrokePyramid module to endow the network with adaptive receptive fields, and two training strategies to achieve faster convergence and augment new stroke sizes upon a trained model respectively. By combining the proposed runtime control strategies, our network can achieve continuous changes in stroke size and produce distinct stroke sizes in different spatial regions within the same output image.

Exemplar-Based Image and Video Stylization Using Fully Convolutional Semantic Features
Feida Zhu, Zhicheng Yan, and Yizhou YuIEEE Transactions on Image Processing, Vol 26, No 7, 2017, PDF
Color and tone stylization in images and videos strives to enhance unique themes with artistic color and tone adjustments. It has a broad range of applications from professional image postprocessing to photo sharing over social networks. Mainstream photo enhancement softwares, such as Adobe Lightroom and Instagram, provide users with predefined styles, which are often hand-crafted through a trial-and-error process. Such photo adjustment tools lack a semantic understanding of image contents and the resulting global color transform limits the range of artistic styles it can represent. On the other hand, stylistic enhancement needs to apply distinct adjustments to various semantic regions. Such an ability enables a broader range of visual styles. In this paper, we first propose a novel deep learning architecture for exemplar-based image stylization, which learns local enhancement styles from image pairs. Our deep learning architecture consists of fully convolutional networks (FCNs) for automatic semantics-aware feature extraction and fully connected neural layers for adjustment prediction. Image stylization can be efficiently accomplished with a single forward pass through our deep network. To extend our deep network from image stylization to video stylization, we exploit temporal superpixels (TSPs) to facilitate the transfer of artistic styles from image exemplars to videos. Experiments on a number of datasets for image stylization as well as a diverse set of video clips demonstrate the effectiveness of our deep learning architecture.

Automatic Photo Adjustment Using Deep Neural Networks
Zhicheng Yan, Hao Zhang, Baoyuan Wang, Sylvain Paris, and Yizhou YuACM Transactions on Graphics, Vol 35, No 2, 2016, [BibTex] (PDF, Supplemental Materials)
Photo retouching enables photographers to invoke dramatic visual impressions by artistically enhancing their photos through stylistic color and tone adjustments. However, it is also a time-consuming and challenging task that requires advanced skills beyond the abilities of casual photographers. Using an automated algorithm is an appealing alternative to manual work but such an algorithm faces many hurdles. Many photographic styles rely on subtle adjustments that depend on the image content and even its semantics. Further, these adjustments are often spatially varying. Existing automatic algorithms are still limited and cover only a subset of these challenges. Recently, deep learning has shown unique abilities to address hard problems. This motivated us to explore the use of deep neural networks in the context of photo editing. In this paper, we formulate automatic photo adjustment in a way suitable for this approach. We also introduce an image descriptor accounting for the local semantics of an image. Our experiments demonstrate that training deep neural networks using these descriptors successfully capture sophisticated photographic styles. In particular and unlike previous techniques, it can model local adjustments that depend on image semantics. We show that this yields results that are qualitatively and quantitatively better than previous work.

An L1 Image Transform for Edge-Preserving Smoothing and Scene-Level Intrinsic Decomposition
Sai Bi, Xiaoguang Han, and Yizhou YuSIGGRAPH 2015, [BibTex], (PDF, Supplemental Materials)
Code Release
Code for L1 image flattening and edge-preserving smoothing can be downloaded here or from GitHub.
Data Download
Edge-preserving smoothing results
Image flattening and intrinsic decomposition results on the Instrinsic-Images-in-the-Wild database (Baidu Cloud, Google Drive)
Identifying sparse salient structures from dense pixels is a long-standing problem in visual computing. Solutions to this problem can benefit both image manipulation and understanding. In this paper, we introduce an image transform based on the L1 norm for piecewise image flattening. This transform can effectively preserve and sharpen salient edges and contours while eliminating insignificant details, producing a nearly piecewise constant image with sparse structures. A variant of this image transform can perform edge-preserving smoothing more effectively than existing state-of-the-art algorithms. We further present a new method for complex scene-level intrinsic image decomposition. Our method relies on the above image transform to suppress surface shading variations, and perform probabilistic reflectance clustering on the flattened image instead of the original input image to achieve higher accuracy. Extensive testing on the Intrinsic-Images-in-the-Wild database indicates our method can perform significantly better than existing techniques both visually and numerically. The obtained intrinsic images have been successfully used in two applications, surface retexturing and 3D object compositing in photographs.
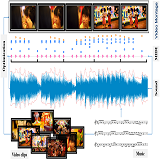
Audeosynth: Music-Driven Video Montage
Zicheng Liao, Yizhou Yu, Bingchen Gong, and Lechao ChengSIGGRAPH 2015, [BibTex], (PDF, Project Webpage)
We introduce music-driven video montage, a media format that offers a pleasant way to browse or summarize video clips collected from various occasions, including gatherings and adventures. In music-driven video montage, the music drives the composition of the video content. According to musical movement and beats, video clips are organized to form a montage that visually reflects the experiential properties of the music. Nonetheless, it takes enormous manual work and artistic expertise to create it. In this paper, we develop a framework for automatically generating music-driven video montages. The input is a set of video clips and a piece of background music. By analyzing the music and video content, our system extracts carefully designed temporal features from the input, and casts the synthesis problem as an optimization and solves the parameters through Markov Chain Monte Carlo sampling. The output is a video montage whose visual activities are cut and synchronized with the rhythm of the music, rendering a symphony of audio-visual resonance.

ColorSketch: A Drawing Assistant for Generating Color Sketches from Photos
Guanbin Li, Sai Bi, Jue Wang, Ying-Qing Xu, and Yizhou YuIEEE Computer Graphics and Applications, Vol 37, No 3, 2017, PDF
A color sketch creates a vivid depiction of a scene using sparse pencil strokes and casual colored brush strokes. In this paper, we introduce an interactive drawing system, called ColorSketch, for helping novice users generate color sketches from photos. Our system is motivated by the fact that novice users are often capable of tracing object boundaries using pencil strokes, but have difficulties to choose proper colors and brush over an image region in a visually pleasing way. To preserve artistic freedom and expressiveness, our system lets users have full control over pencil strokes for depicting object shapes and geometric details at an appropriate level of abstraction, and automatically augment pencil sketches using color brushes, such as color mapping, brush stroke rendering as well as blank area creation. Experimental and user study results demonstrate that users, especially novice ones, can generate much better color sketches more efficiently with our system than using traditional manual tools.

Example-Based Image Color and Tone Style Enhancement
Baoyuan Wang, Yizhou Yu, and Ying-Qing XuSIGGRAPH 2011, [BibTex], (PDF, Supplemental Materials)
Color and tone adjustments are among the most frequent image enhancement operations. We define a color and tone style as a set of explicit or implicit rules governing color and tone adjustments. Our goal in this paper is to learn implicit color and tone adjustment rules from examples. That is, given a set of examples, each of which is a pair of corresponding images before and after adjustments, we would like to discover the underlying mathematical relationships optimally connecting the color and tone of corresponding pixels in all image pairs. We formally define tone and color adjustment rules as mappings, and propose to approximate complicated spatially varying nonlinear mappings in a piecewise manner. The reason behind this is that a very complicated mapping can still be locally approximated with a low-order polynomial model. Parameters within such low-order models are trained using data extracted from example image pairs. We successfully apply our framework in two scenarios, low-quality photo enhancement by transferring the style of a high-end camera, and photo enhancement using styles learned from photographers and designers.

Data-Driven Image Color Theme Enhancement
Baoyuan Wang, Yizhou Yu, Tien-Tsin Wong, Chun Chen, and Ying-Qing XuSIGGRAPH Asia 2010, [BibTex], (PDF, Supplemental Materials)
It is often important for designers and photographers to convey or enhance desired color themes in their work. A color theme is typically defined as a template of colors and an associated verbal description. This paper presents a data-driven method for enhancing a desired color theme in an image. We formulate our goal as a unified optimization that simultaneously considers a desired color theme, texture-color relationships as well as automatic or user-specified color constraints. Quantifying the difference between an image and a color theme is made possible by color mood spaces and a generalization of an additivity relationship for two-color combinations. We incorporate prior knowledge, such as texture-color relationships, extracted from a database of photographs to maintain a natural look of the edited images. Experiments and a user study have confirmed the effectiveness of our method.

Speaker-Following Video Subtitles
YONGTAO HU, JAN KAUTZ, YIZHOU YU, and WENPING WANGACM Transactions on Multimedia Computing, Communication and Applications, Vol 11, No 2, 2014 , (PDF)
We propose a new method for improving the presentation of subtitles in video (e.g., TV and movies). With conventional subtitles, the viewer has to constantly look away from the main viewing area to read the subtitles at the bottom of the screen, which disrupts the viewing experience and causes unnecessary eyestrain. Our method places on-screen subtitles next to the respective speakers to allow the viewer to follow the visual content while simultaneously reading the subtitles. We use novel identification algorithms to detect the speakers based on audio and visual information. Then the placement of the subtitles is determined using global optimization. A comprehensive usability study indicated that our subtitle placement method outperformed both conventional fixed-position subtitling and another previous dynamic subtitling method in terms of enhancing the overall viewing experience and reducing eyestrain.

Single-View Hair Modeling for Portrait Manipulation
Menglei Chai, Lvdi Wang, Yanlin Weng, Yizhou Yu, Baining Guo, and Kun ZhouSIGGRAPH 2012, PDF
Human hair is known to be very difficult to model or reconstruct. In this paper, we focus on applications related to portrait manipulation and take an application-driven approach to hair modeling. To enable an average user to achieve interesting portrait manipulation results, we develop a single-view hair modeling technique with modest user interaction to meet the unique requirements set by portrait manipulation. Our method relies on heuristics to generate a plausible high-resolution strand-based 3D hair model. This is made possible by an effective high-precision 2D strand tracing algorithm, which explicitly models uncertainty and local layering during tracing. The depth of the traced strands is solved through an optimization, which simultaneously considers depth constraints, layering constraints as well as regularization terms. Our single-view hair modeling enables a number of interesting applications that were previously challenging, including transferring the hairstyle of one subject to another in a potentially different pose, rendering the original portrait in a novel view and image-space hair editing.

Interactive Image Segmentation Based on Level Sets of Probabilities
Yugang Liu and Yizhou YuIEEE Transactions on Visualization and Computer Graphics, Vol 18, No 2, 2012, [BibTex], PDF
In this paper, we present a robust and accurate levelset based algorithm for interactive image segmentation. The level set method is clearly advantageous for image objects with a complex topology and fragmented appearance. Our method integrates discriminative classification models with the level set method to better avoid local minima. Our level set function approximates a posterior probabilistic mask of a foreground object. The evolution of its zero level set is driven by three force terms, region force, edge field force, and curvature force. These forces are based on a probabilistic classifier and an unsigned distance transform of salient edges. We further apply expectation-maximization to improve the performance of both the probabilistic classifier and the level set method over multiple passes. Experiments and comparisons demonstrate the superior performance of our method.
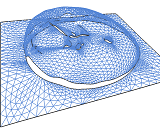
A Subdivision-Based Represenation for Vector Image Editing
Zicheng Liao, Hugues Hoppe, David Forsyth, and Yizhou YuIEEE Transactions on Visualization and Computer Graphics, Vol 18, No 11, 2012 (spotlight paper), PDF
Vector graphics has been employed in a wide variety of applications due to its scalability and editability. Editability is a high priority for artists and designers who wish to produce vector-based graphical content with user interaction. In this paper, we introduce a new vector image representation based on piecewise smooth subdivision surfaces, which is a simple, unified and flexible framework that supports a variety of operations, including shape editing, color editing, image stylization, and vector image processing. These operations effectively create novel vector graphics by reusing and altering existing image vectorization results. Because image vectorization yields an abstraction of the original raster image, controlling the level of detail of this abstraction is highly desirable. To this end, we design a feature-oriented vector image pyramid that offers multiple levels of abstraction simultaneously. Our new vector image representation can be rasterized efficiently using GPU-accelerated subdivision. Experiments indicate that our vector image representation achieves high visual quality and better supports editing operations than existing representations.

Patch-Based Image Vectorization with Automatic Curvilinear Feature Alignment
Tian Xia, Zicheng(Binbin) Liao, and Yizhou YuSIGGRAPH Asia 2009, PDF
Raster image vectorization is increasingly important since vectorbased graphical contents have been adopted in personal computers and on the Internet. In this paper, we introduce an effective vectorbased representation and its associated vectorization algorithm for full-color raster images. There are two important characteristics of our representation. First, the image plane is decomposed into nonoverlapping parametric triangular patches with curved boundaries. Such a simplicial layout supports a flexible topology and facilitates adaptive patch distribution. Second, a subset of the curved patch boundaries are dedicated to faithfully representing curvilinear features. They are automatically aligned with the features. Because of this, patches are expected to have moderate internal variations that can be well approximated using smooth functions. We have developed effective techniques for patch boundary optimization and patch color fitting to accurately and compactly approximate raster images with both smooth variations and curvilinear features. A real-time GPU-accelerated parallel algorithm based on recursive patch subdivision has also been developed for rasterizing a vectorized image. Experiments and comparisons indicate our image vectorization algorithm achieves a more accurate and compact vector-based representation than existing ones do.

Lazy Texture Selection Based on Active Learning
Tian Xia, Qing Wu, Chun Chen, and Yizhou YuThe Visual Computer, Vol 26, No 3, 2010, PDF
It imposes a great challenge to select desired textures and textured objects across both spatial and temporal domains with minimal user interaction. This paper presents a method for achieving this goal. With this method, the appearance of similar texture regions within an entire image or video can be simultaneously manipulated. The technique we developed applies the active learning methodology. The user only needs to label minimal initial training data and subsequent query data. An active learning algorithm uses these labeled data to obtain an initial classifier and iteratively improves it until its performance becomes satisfactory. A revised graph cut algorithm based on the trained classifier has also been developed to improve the spatial coherence of selected texture regions. A variety of operations, such as color editing, matting and texture cloning, can be applied to the selected textures to achieve interesting editing effects.
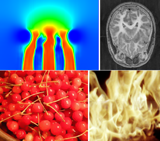
Hierarchical Tensor Approximation of Multi-Dimensional Visual Data
Qing Wu, Tian Xia, C. Chen, H.-Y. Lin, H. Wang and Yizhou YuIEEE Transactions on Visualizationa and Computer Graphics, Vol 14, No 1, 2008, PDF
Visual data comprise of multi-scale and inhomogeneous signals. In this paper, we exploit these characteristics and develop a compact data representation technique based on a hierarchical tensor-based transformation. In this technique, an original multi-dimensional dataset is transformed into a hierarchy of signals to expose its multi-scale structures. The signal at each level of the hierarchy is further divided into a number of smaller tensors to expose its spatially inhomogeneous structures. These smaller tensors are further transformed and pruned using a tensor approximation technique. Our hierarchical tensor approximation supports progressive transmission and partial decompression. Experimental results indicate that our technique can achieve higher compression ratios and quality than previous methods, including wavelet transforms, wavelet packet transforms, and single-level tensor approximation. We have successfully applied our technique to multiple tasks involving multi-dimensional visual data, including medical and scientific data visualization, data-driven rendering and texture synthesis.

Out-of-Core Tensor Approximation of Multi-Dimensional Matrices of Visual Data
Hongcheng Wang, Qing Wu, Lin Shi, Yizhou Yu and Narendra AhujaSIGGRAPH 2005, [BibTex], PDF
Tensor approximation is necessary to obtain compact multilinear models for multi-dimensional visual datasets. Traditionally, each multi-dimensional data item is represented as a vector. Such a scheme flattens the data and partially destroys the internal structures established throughout the multiple dimensions. In this paper, we retain the original dimensionality of the data items to more effectively exploit existing spatial redundancy and allow more efficient computation. Since the size of visual datasets can easily exceed the memory capacity of a single machine, we also present an out-of-core algorithm for higher-order tensor approximation. The basic idea is to partition a tensor into smaller blocks and perform tensor-related operations blockwise. We have successfully applied our techniques to three graphics-related data-driven models, including 6D bidirectional texture functions, 7D dynamic BTFs and 4D volume simulation sequences. Experimental results indicate that our techniques can not only process out-of-core data, but also achieve higher compression ratios and quality than previous methods.

Feature Matching and Deformation for Texture Synthesis
Qing Wu and Yizhou YuSIGGRAPH 2004, PDF
One significant problem in patch-based texture synthesis is the presence of broken features at the boundary of adjacent patches. The reason is that optimization schemes for patch merging may fail when neighborhood search cannot find satisfactory candidates in the sample texture because of an inaccurate similarity measure. In this paper, we consider both curvilinear features and their deformation. We develop a novel algorithm to perform feature matching and alignment by measuring structural similarity. Our technique extracts a feature map from the sample texture, and produces both a new feature map and texture map. Texture synthesis guided by feature maps can significantly reduce the number of feature discontinuities and related artifacts, and gives rise to satisfactory results.