|
High-Resolution
Shape Completion Using Deep Neural Networks for
Global Structure and Local Geometry Inference Xiaoguang Han*, a, Zhen
Li*,a, Haibin Huangb, Evangelos Kalogerakisb, Yizhou Yua a The University of Hong Kong, b UMass Amherst (* indicates equal
contribution) ICCV 2017
(Spotlight) |
|||
|
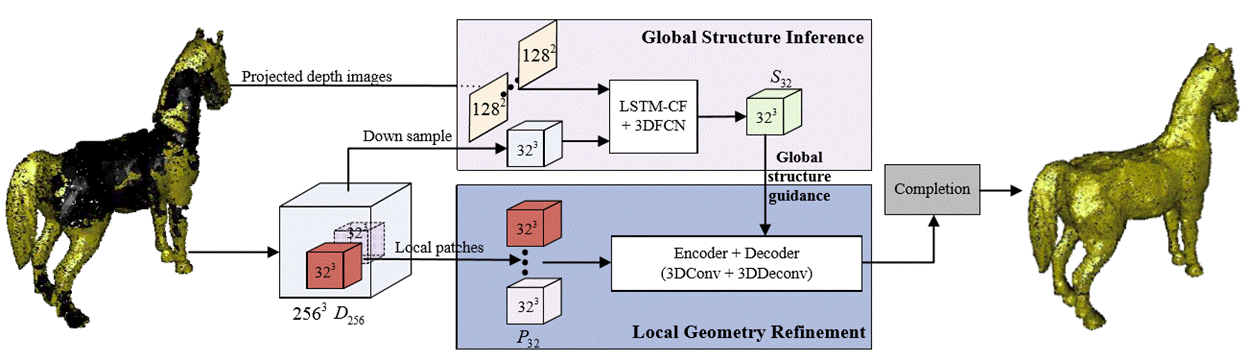
Figure
1: Pipeline of our high-resolution shape completion method. Given a 3D shape
with large missing regions, our method outputs a complete shape through global
structure inference and local geometry refinement. Our architecture
consists of two jointly trained sub-networks: one network predicts the global
structure of the shape while the other locally generates the repaired surface
under the guidance of the first network. |
|||
|
Abstract |
We
propose a data-driven method for recovering missing parts of 3D shapes. Our
method is based on a new deep learning architecture consisting of two
sub-networks: a global structure inference network and a local geometry refinement
network. The global structure inference network incorporates a long
short-term memorized context fusion module (LSTM-CF) that infers the global
structure of the shape based on multi-view depth information provided as part
of the input. It also includes a 3D fully convolutional (3DFCN) module that
further enriches the global structure representation according to volumetric
information in the input. Under the guidance of the global structure network,
the local geometry refinement
network takes as input local 3D patches around missing regions, and
progressively produces a high-resolution, complete surface through a volumetric encoder-decoder architecture. Our method
jointly trains the global structure inference and local geometry refinement
networks in an end-to-end manner. We perform qualitative and quantitative
evaluations on six object categories, demonstrating that our method
outperforms existing state-of-the-art work on shape completion. |
||
|
Download |
|
||
|
Network
Architecture |
|||
|
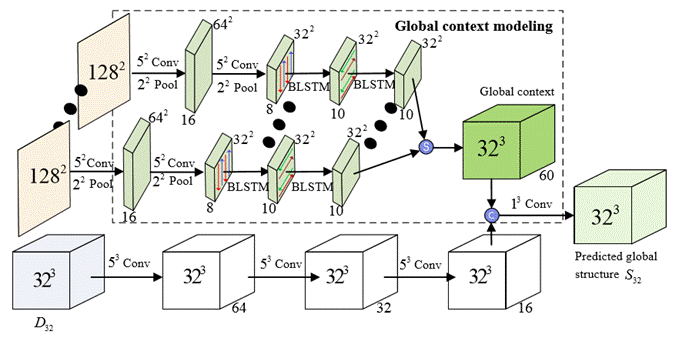
Figure
2: The inputs for global structure inference consist of projected depth
images with size 1282 and down-sampling voxelized
point cloud D32 with resolution 323. “S” stands for the feature
stack operation. “C” stands for the concatenate operation. |
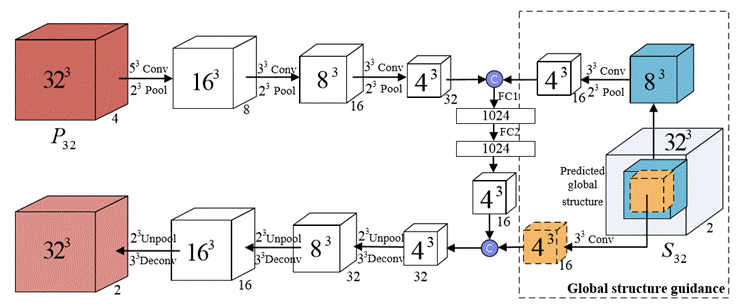
Figure
3: The inputs of local surface refinement network consist of local
patches P32 with size 323 and output S32 with size 323 from the global
structure inference network as global guidance. |
||
|
Results
Gallery |
|||
|
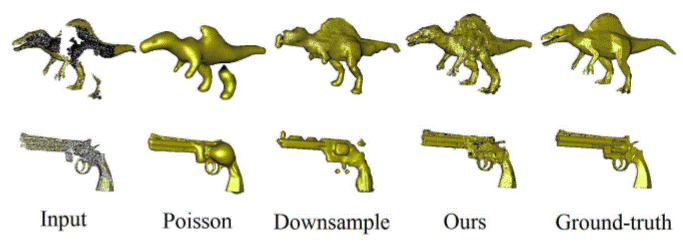
Figure 4: Gallery of final results. There are two models per category. For each model, the input and repaired point clouds are shown side by side from two different views. |
|||
|
Evaluation |
|||
|
Table 1: Performance Comparison. For
each category and each method, we show the value of completeness/normalized
dist. |
|||
|
Figure 5: Sampled comparison results
with other methods. |
Figure 6:
Completion results by using our model with and without global guidance. |
||
|
Acknowledgements |
The
authors would like to thank the reviewers for their constructive comments. Evangelos Kalogerakis
acknowledges support from NSF (CHS1422441, CHS-1617333). |
||
|
Bibtex |
@inproceedings{HRSC, |
||



Copyright
© 2017 Xiaoguang Han