Welcome to Haley Kwok’s FYP project!
I am working individually under the supervision of Dr. Z. Y. Huang, towards the topic “Theorectical Research on Online Matching”.
Table of context
Introduction
So what is Online Matching?
The “matching” here is referring to “Graph Matching” here. If you happened to be a UG student who is fond of algorithms, you might recall that you have heard this term from algorithmatic courses such as COMP3351 Advanced Algorithm Analysis, COMP3352 Game Theory.
What if I have never heard the topic?
You are most definitely missing out one of the most important classic algorithmatic field in the community, and should definitely read up some information about it due to its wide range of application. For example, matching algorithm is used for administrative purposes in the campus, such as allocating dorms and admitting new students.
Owing to its popularity, I could guarantee you to find some chapters in any algorithmatic introductory textbooks at introductory level. However, if you have never heard of graph matching, chances are – You don’t have one with you, do you? As a workaround, we suggest you to check out this video by Udacity to learn the basics.
If you prefer reading text
You may check out the wiki article that is fairly well written, or the appendices of the Detailed Project Plan.
Research Scope
Isn’t “Graph Matching” a solved problem? What are trying to achieve with this project?
While the Graph Matching problem has been solved in the classical (i.e. offline) setting, a lot of questions remains to be unsolved in the online setting.
You kept bringing this “Online” term up, what difference does it make?
In the context of algorithm analysis, whenever we say some problem is “online”, we mean that not all information is available to the algorithm at the time of initialization, and they are revealed eventually as the algorithm runs. To demonstrate the difference, let’s consider the difference between Bachelor and PhD admissions.
Bachelor admissions
Bachelor degree offers are handed out on a yearly basis. The JUPAS system gathers all the information before it makes an informed decision, such as slots offered by each degree programme, applicants' preferences and their public examination transcripts. Just as what good ol' Uncle John prooooobably said, "With perfect information comes perfect solution".
 The JUPAS office collects all information before making an informed decision
The JUPAS office collects all information before making an informed decision
PhD admissions
On the other hand, PhD applications are handled in a rolling basis in HKU CS. After the department opens for Phd applications on September, applications begin to flood in throughout the year. If the professors were to handle the admission only after the application process is closed on May, there is simply no hope for them to go through all of them, and students may have already accepted some other institutions' offer instead.
 The department has to handle applications whenever they come in
The department has to handle applications whenever they come in
Under this analogy, the Online Matching problem is not solved, not because of the state-of-the-art algorithm incapability in performing optimally, but incapability in meeting our expected optimal performance – We are either over optimistic with what the law of nature permits us to achieve, or too dumb to find a better algorithm, or perhaps both of them.
What model / methodology does the project use?
The analysis is expected to be carried out under the Randomized Primal-Dual framework. If this happens to be the first time you came across analysis done with dual Linear Programming, please take a look at this excellent video by Georgia Tech introducing the concept of duality in the context of maximum graph matching.
Furthermore, it is highly likely that the work will be done under the fully online model. For a more detailed coverage of technical details, please read the appendices of the Detailed Project Plan.
Project Progress
Current stage:
Scruntizing papers and crunching numbers, understanding the approaches used by the current research frontier.
Schedule
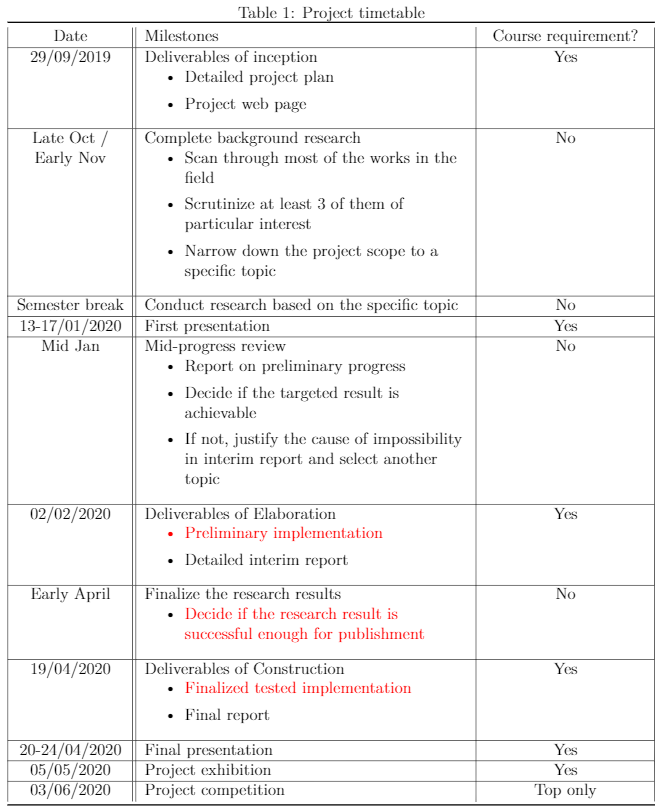
This is a tentative schedule extracted from the Detailed Project Plan.
Documentations
Detailed Project Plan (Updated on 17 Oct)