Figure 1: DeepFashion dataset fashion image samples.
Abstract
This project aims to review and explore the applications of a fashion editing network, and propose a design for a GUI application of the network with enhanced interactive editing features. In addition, this project explores the possibility of adaptation of convolutional networks to embedded systems equipped with specialized hardware with limited computing power for such application.
Background. Advancement in convolutional network architecture and training techniques in recent years has enabled the automation of high-level image processing tasks, such as image segmentation [1, 2], image reconstruction and manipulation [3, 4], and fashion-related applications [5, 6, 7].
Fashion editing. Fashion image editing aims to modify real fashion images with user-provided color sketches to produce realistic and pleasing results. As opposed to commercial image-editing software such as Adobe Photoshop which requires a substantial amount of human skill and labour to achieve similar results, a fashion editing network, which can gain a high-level semantic understanding of the images via training of network parameters, enables low-effort manipulation of fashion images without prior experience in fashion design.
Fashion editing network and application. In this project, the architecture of a fashion editing network Fashion Editing Generative Adversarial Network (FE-GAN) [5] is reviewed, and a fashion editing GUI application is designed to demonstrate ways to achieve a more feature-rich and convenient experience in interactive manipulation of fashion images. Various tools and controls features are proposed for the application, including mask morphing, edge detection, skin color detection, zoom-in and export facilities, predefined patterns, keyboard shortcuts and checkerboard fill background.
Experiment with segmentation network on embedded device. Furthermore, in light of the increasing adoption of convolutional networks in embedded devices for daily life applications, an experiment is conducted to quantize and convert convolutional networks for inference on a commercial small single-board computer equipped with specialized hardware for tensor operations. In addition, the limitation in computing capability and performance of such embedded systems motivates further improvements in network quantization and architecture optimization to increase inference performance. A modification in encoder-decoder is proposed for segmentation network SegNet [8] and a small training experiment is performed. The qualitative and quantitive performance of the modified network is then evaluated. The modified network is further quantized and converted for inference on the single-board computer hardware for evaluation.
Fashion dataset. The DeepFashion [9] dataset, which consists of high-resolution professionally shot fashion images with varying pose, viewpoint and background, is used in the training and testing of the fashion editing network.
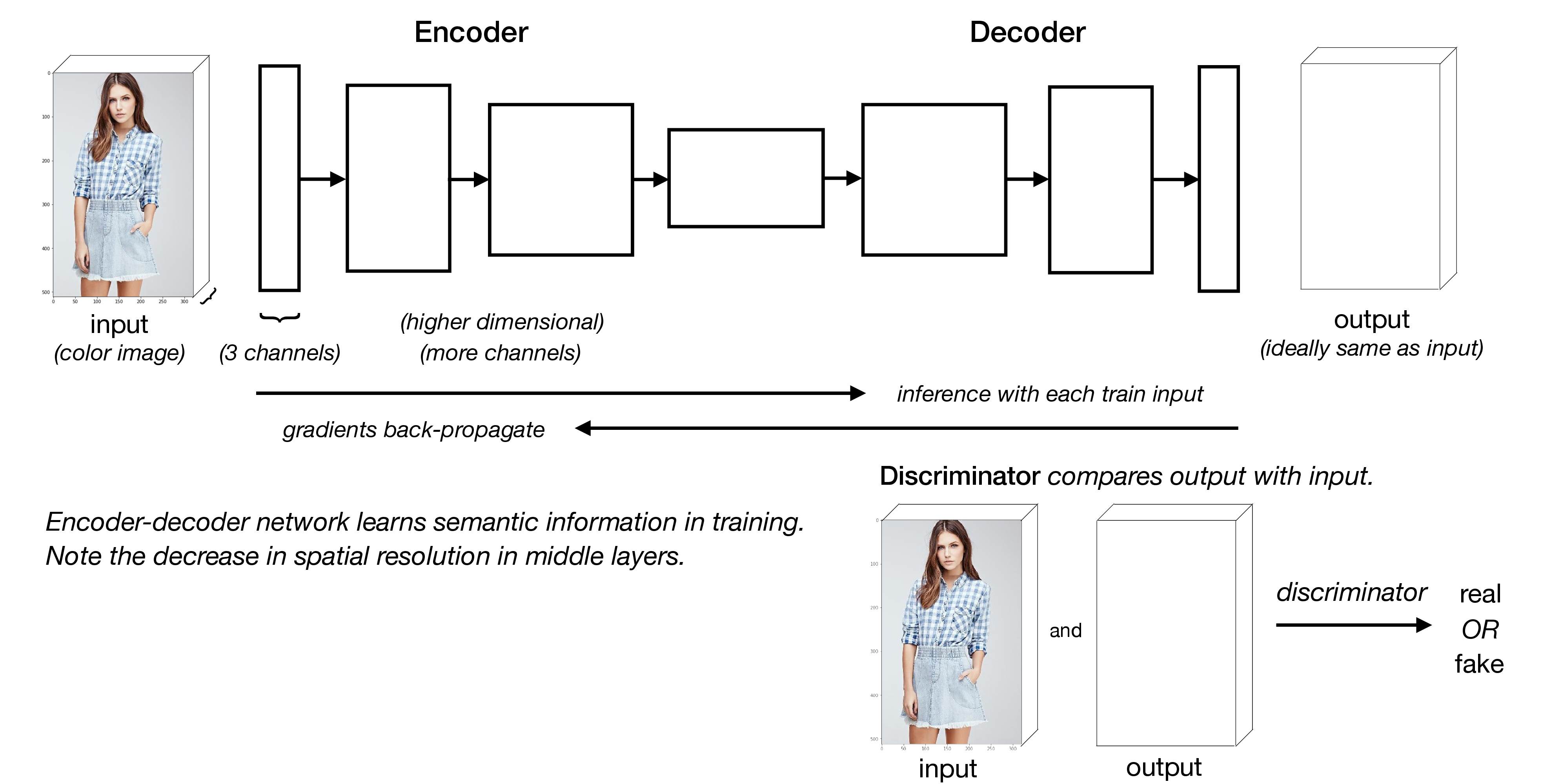
Generative Adversarial Network. A simple description of Generative Adversarial Network (GAN), which forms the base architecture of Fashion Editing Generative Adversarial Network (FE-GAN) [5, 6], is given as follows with an illustration provided in Figure 2. The network consists of a generator, which is an encoder-decoder network with an hour-glass shape, and a discriminator. Note that a noise layer or channel is usually concatenated with the input image channel(s) along the channel dimension.
Layers of input to fashion editing network. In a fashion editing network, a total of 10 channels with the same dimension as the input image are concatenated along the channel dimension, including the original RGB image (3 channels), a binary mask representing the erased portions (1 channel), a binary outline sketch describing structure of parts to be reconstructed (1 channel), a RGB color stroke map (3 channels), a synthesized new segmentation map for the intended RGB image result (1 channel) and a Gaussian noise (1 channel). Note that the Gaussian noise is essential in the training of GANs for non-determinism and better convergence.
Synthesized segmentation mask. After user modification to the fashion image, the correct segmentation labels for the edited areas may differ from that in the segmentation for the unedited image. For example, a change in correct segmentation label may result from a sketch and mask combination intended to replace pixels depicting clothing with synthesized pixels depicting skin, or vice versa. Therefore, a new segmentation label is synthesized to assign category labels inferred from the segmentation label of the unchanged neighboring areas and user-supplied outline sketches.
Post-processing of network output. Unmasked parts of the fashion image are not guaranteed to be the preserved by the network, and therefore such parts are replaced with the corresponding parts from the original image by masking operations. However, such operations may produce a resulting image where apparently artificial modification or addition is applied. To improve the visual appearance of the resulting image, it is proposed that a seamless combination of the original image and network output image can be obtained by using a Gaussian blurred mask for combination to ensure a smooth transition at the boundary of masked areas.
Limitation of network. The fashion editing network FE-GAN is limited in producing desirable realistic results for fashion images with complex patterns and inaccurate sketches. For example, a sketch without gradient color paint for edited areas for a gradient colored fashion item would lead to a resulting image that looks unrealistic. The network works better on images of fashion items with simple designs.
A Graphical User Interface (GUI) application design is proposed to achieve a more feature-rich and convenient experience in interactive manipulation of fashion images, compared to the pre-existing primitive demo application adapted from [10].
Figure 3 shows part of an edited input image seen by the user in the editing window and the corresponding output of the network. Note that the edited input image is a rendering of separate layers including image, mask, sketch and color stroke.
The main tools of the demo application are to be restructured and renamed as Eraser, Pencil and Paint for intuitive understanding by users.
Eraser, which is intuitively presented to users as removing parts of an image, produces a mask layer to be used as input to the fashion editing network.
Pencil, which is intuitively presented to users as sketching black outlines on the image, produces a sketch layer to be used as input to the fashion editing network.
This tool may be further improved by replacing Canny edge detector with a deep learned semantic edge detector such as holistically-nested edge detection (HED) [13], provided that the outline layers used in training are also generated with such detector or hand-drawn to match its outline structure composed of thick and thin lines.
Paint, which is intuitively presented to users as putting colors picked from color-wheel on the image, produces a stroke layer to be used as input to the fashion editing network.
Zoom-in facility, which is useful for fine-grained edits that operate on an area spanning only a few pixels, enables an enlarged view of specific parts of a fashion image in the working window by mouse scrolling.
Export facility, which is useful for storing and sharing of sketches and masks in a multi-layer format, enables preservation of the masks and sketches in separate layers for future editing sessions.
Keyboard shortcut support, which is useful for implementing a smooth editing workflow without altering the current cursor position, enables quick access of frequently used tools and controls while drawing.
Fast-rewind for undo and fast-forward redo, which is useful for undo or redoing the drawing of a complex item that is composed of multiple edits and strokes, enables quick undoing or redoing of multiple steps by dragging the handle of a slider. This control feature may be further improved to intelligently group edits and strokes for a semantic undo and redo function.
Predefined patterns, which is useful for quick edits of fashion images with minimal artistic skill and effort, enables one-click stamping application of patterns including (i) textures such as stripes, floral patterns, skin and hair, and (ii) accessory items such as handbags, shoes and hats.
Checkerboard background for erased mask regions as illustrated in Figure 5 that can be switched on from a white background in the edited image, which is useful for displaying of erased portions as different from white-colored pixels, provides intuition for further application of sketches and strokes in the masked regions.
Doodling application. An interesting side application of the fashion editing network or a similar generative network is a free-drawing application with automatic conversion of user-supplied sketch and paint (preferably of a similar style as training images) on a completely masked canvas (effectively a blank background) to a completely filled realistic looking image. An example is shown in Figure 61.
Colorization application. In addition, a colorization application can be achieved by providing pre-generated edges of fashion images as templates for free drawing with color strokes.
Motivation. Embedded systems equipped with special hardware for tensor operations enable low-cost, server-less and mobile applications of convolutional networks. To explore the possibility of porting the GUI application proposed to run locally on embedded device systems, and, in particular, the possibility of porting the convolutional networks as backend of the application to embedded device systems, an experiment is performed on a simple convolutional network for segmentation, with the aim to eventually convert a complex convolutional network such as the fashion editing network with more complicated layers for inference on embedded systems.
Embedded device. A commercial small single-board computer equipped with specialized hardware customized for tensor operations2, which alleviates the limitation of such single-board computer in computing capability and performance, is selected for this experiment.
Segmentation network. The network chosen in this experiment is a single unified segmentation network SegNet [8], which can be used for on-device segmentation of user-provided photographic images without the need for the user to supply an accompanying segmentation mask before further applications such as fashion editing. SegNet (2016) has an encoder-decoder architecture improved with the introduction of Unpooling boolean mask and skip connections to combine semantic information of large and small receptive fields.
Fashion segmentation dataset. Fashion images and labels are obtained from the CIHP (Crowd Instance-level Human Parsing) dataset [19] for human parsing/segmentation tasks, which includes 28280 training, 5000 validation and 5000 test images cropped multi-person instances from Microsoft COCO dataset [20]. Note that in the labeling of training data, the 20 category definitions proposed for Look Into Person [21] and CIHP (Crowd Instance-level Human Parsing) dataset [19], as follows: __Background, __Hat, __Hair, __Glove, __Sunglasses, __Upper-clothes, __Dress, __Coat, __Socks, __Pants, __Jumpsuits, __Scarf, __Skirt, __Face, __Left-arm, __Right-arm, __Left-leg, __Right-leg, __Left-shoe, __Right-shoe.
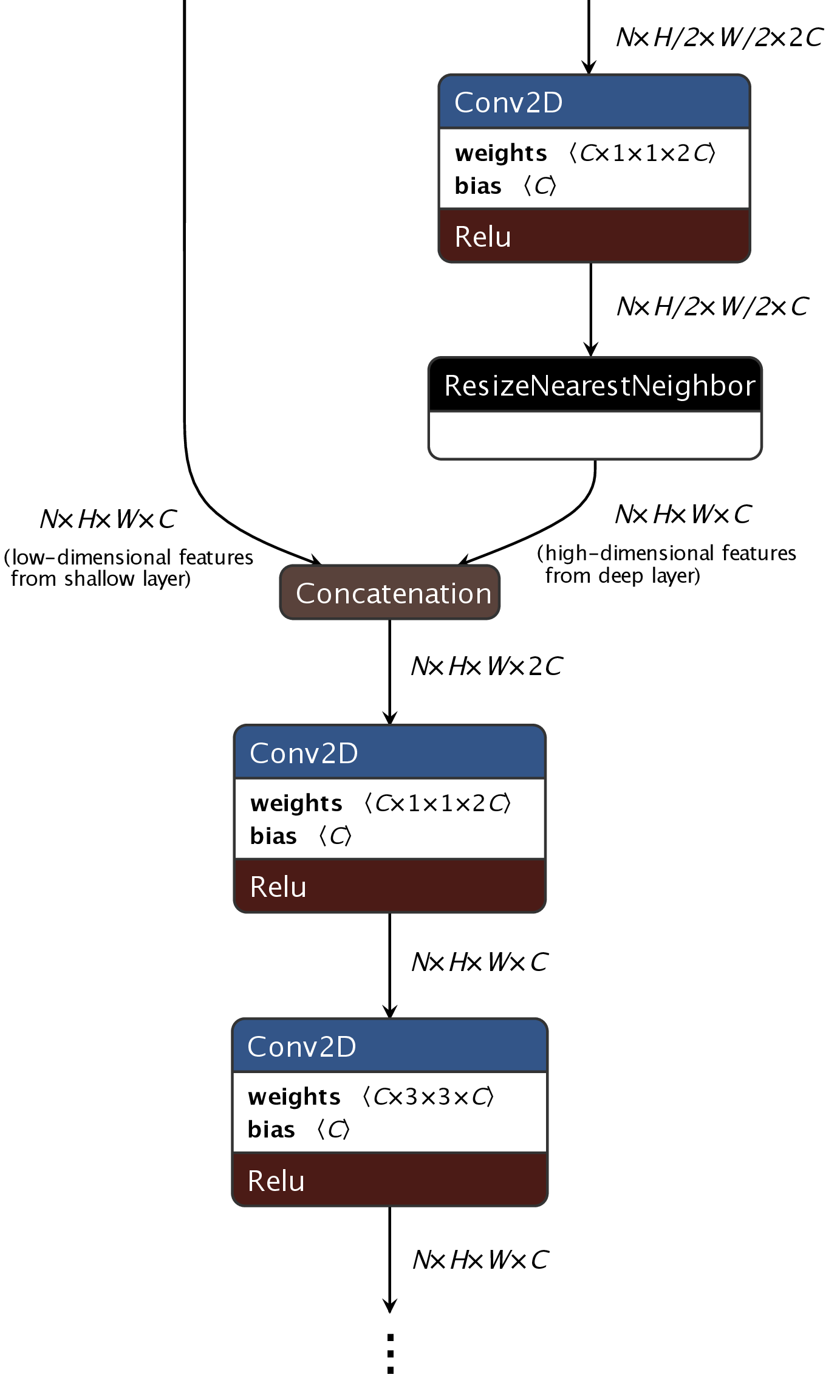
Motivation for decoder modification. The network is trained with the fashion images and labels, integer-quantized3, and converted to run on the single-board computer. Due to limited support of instructions for the special hardware, including the lack of support for CAST for boolean-to-integer conversion and EQUAL for element-wise equality used in the Unpooling layer [24] in SegNet, the non-trainable Unpooling layer is replaced with a trainable decoder scheme for feature fusion proposed as illustrated in Figure 7.
Feature fusion in decoder. The link to low-dimensional features from a shallow layer effectively functions as a residual connection4, which can increase training speed as network converges faster. A 1 × 1 point-wise convolution layer is added on the two branches concatenated along the channel dimension, followed by a ReLU non-linearity to prevent collapse of the 1 × 1 convolution layer into the 3 × 3 convolution layer that follows.
Dimensions and number of parameters. With the modification by introduction of the decoder scheme, total parameter count of the network slightly increased from 29.5 million to 30.7 million for dimension choices: channels C = {64,128,256,512,512}5 and height and width H = W = {320,160,80,40,20}.
Comparison with DeepLab v3+ decoder. The proposed decoder scheme as a method for high/low-dimensional feature concatenation is found to be similar to that in DeepLab v3+ (2018) [25]. However, there are two major differences. Firstly, for upsampling, we use nearest neighbor instead of bilinear interpolation, which can perform slightly better but is more computationally expensive [26]. Secondly, after concatenation of high-dimensional features (downsampled in depth and then upsampled in spatial resolution) and low-dimensional features with the same spatial dimension, we use a 1 × 1 convolution to reduce the number of channels followed by ReLU non-linearity before fine-tuning with 3 × 3 convolutions instead of directly applying a 3 × 3 convolution on concatenated input features. Both of these choices reduce computational complexity, and also may be able to better preserve spatial correspondence between the high-dimensional features and low level features.
Potential modifications to be experimented. Note that identity mapping residual connections within each convolution block as in ResNet [27] are not used but may be added for potential further improvement in segmentation. Further experiments are yet to be carried out on human parsing for using the idea of dense connections for deep supervision in DenseNet [28] and its adaption for densely connected skip connections for segmentation tasks in UNet++ [29] with transposed convolution [30] for upsampling.
Issue that remains for SegNet models. The results from both SegNet (2016) and the modified SegNet show confusion over position labels pairs: Left-arm and Right-arm; Left-leg and Right-leg; Left-shoe and Right-shoe. It is hypothesized that this is due to the lack of explicit modeling of pose information in both networks. New state-of-the-art models such as LIP-JPPNet [21] and Graphonomy [31], which explicitly model pose information or spatial proximity relationship and adopt other boosting techniques, produce much more promising results than SegNet, which is evident by the quantitative figures in Figure 8.
| Method | Pixel Accuracy | Mean IoU6 |
| Modified SegNet | 86.1% | 44.0% |
| DeepLab v3+ [25] | 57.1% | |
| Graphonomy [31] | 57.7% | |
Improvement. The proposed modified SegNet performs qualitatively better than SegNet (2016) for the segmentation task, as observed from examples shown in Figure 9. The results from SegNet (2016) show confusion over the correct label for a pants segment in the first image and for a background segment where a musical instrument is present in the second image. This issue is not seen in results from modified SegNet.
Issue with quantization. The modified network is further integer-quantized and converted for inference on the single-board computer hardware. The qualitative result of inference with the quantized network as exemplified in Figure 10 is unsatisfactory. Large patches of non-background area in the ground truth label are classified as background. It is hypothesized that dead activations result from the accumulation of post-training integer-quantization precision loss over repeated subsampling operations, as the input image goes through a series of decoders in network. This loss of information is an inherent problem of the encoder-decoder architecture. It is suggested that FlatteNet [32], which produces dense pixel-wise predictions for objection detections, may be explored and adapted for pixel-wise segmentation.
In this project, the architecture of Fashion Editing Generative Adversarial Network (FE-GAN) is reviewed, the applications of the fashion editing network are explored, and a design for a GUI application of the network with enhanced interactive editing features is proposed. In addition, the possibility of adaptation of convolutional networks to embedded systems is explored through an experiment in converting a modified SegNet to run on a commercial single-board computer with specialized hardware for accelerated network inference, in which unsatisfactory results are obtained indicating rooms for improvement in network design and/or conversion.
Network architecture improvements. Much work in network design, quantization and/or conversion need to be done to enable successful conversion of large encoder-decoder models for embedded device systems.
An augmented reality fashion application. Real-time applications with video streamed from a camera connected to the single-board computer can be developed to make use of the special hardware network accelerator’s high inference speed for high frame-rate applications of encoder-decoder networks, such as augmented reality applications in social media applications or fashion stores providing virtual clothes try-on and clothing customization, which often involve complicated fashion item designs and inaccurate user input.
An enhanced editing application with hardware for drawing. A graphic drawing tablet7 with physical buttons an be found useful in the building of a physical button-controlled user interface, and a high-resolution pen stylus that records cursor hover events and pressure levels can be used with software design updates to create a smooth user experience in fashion editing compared to editing with a mouse connected to a computer.
Sincere gratitude is expressed to supervisor Prof. Luo, Ping and his colleagues for their generous advice on the understanding of convolutional networks and help on brainstorming of ideas for this project.
[1] S. Minaee, Y. Boykov, F. Porikli, A. Plaza, N. Kehtarnavaz, and D. Terzopoulos, “Image Segmentation Using Deep Learning: A Survey,” p. 24, 2020.
[2] M. Thoma, “A Survey of Semantic Segmentation,” arXiv:1602.06541 [cs], May 2016.
[3] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Free-Form Image Inpainting with Gated Convolution,” arXiv:1806.03589 [cs], Jun. 2018.
[4] G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolutions,” arXiv:1804.07723 [cs], Dec. 2018.
[5] H. Dong, X. Liang, Y. Zhang, X. Zhang, Z. Xie, B. Wu, Z. Zhang, X. Shen, and J. Yin, “Fashion Editing with Adversarial Parsing Learning,” arXiv:1906.00884 [cs, eess], Sep. 2019.
[6] H. Dong, X. Liang, Y. Zhang, X. Zhang, Z. Xie, B. Wu, Z. Zhang, X. Shen, and J. Yin, “Fashion Editing with Multi-scale Attention Normalization,” arXiv:1906.00884 [cs, eess], Jun. 2019.
[7] H. Yang, R. Zhang, X. Guo, W. Liu, W. Zuo, and P. Luo, “Towards Photo-Realistic Virtual Try-On by Adaptively Generating Preserving Image Content,” arXiv:2003.05863 [cs, eess], Mar. 2020.
[8] V. Badrinarayanan, A. Kendall, and R. Cipolla, “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation,” arXiv:1511.00561 [cs], Oct. 2016.
[9] Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang, “DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, Jun. 2016, pp. 1096–1104.
[10] Y. Jo and J. Park, “SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color,” arXiv:1902.06838 [cs], Feb. 2019.
[11] W. Burger and M. Burge, Principles of Digital Image Processing: Core Algorithms, ser. Undergraduate Topics in Computer Science. London: Springer, 2009.
[12] J. Canny, “A Computational Approach to Edge Detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PAMI-8, no. 6, pp. 679–698, Nov. 1986.
[13] S. Xie and Z. Tu, “Holistically-Nested Edge Detection,” arXiv:1504.06375 [cs], Oct. 2015.
[14] A. Odena, V. Dumoulin, and C. Olah, “Deconvolution and Checkerboard Artifacts,” Distill, vol. 1, no. 10, p. e3, Oct. 2016.
[15] O. Temam, H. Khaitan, R. Narayanaswami, and D. H. Woo, “Neural network accelerator with parameters resident on chip,” US Patent US20 190 050 717A1, Feb., 2019.
[16] Q-engineering, “Google Coral Edge TPU explained in depth - Q-engineering.”
[17] NVIDIA, “NVIDIA Jetson NANO Developer Kit Datasheet,” p. 2, 2019.
[18] Q-engineering, “Deep learning with Raspberry Pi and alternatives,” 2019.
[19] K. Gong, X. Liang, Y. Li, Y. Chen, M. Yang, and L. Lin, “Instance-Level Human Parsing via Part Grouping Network,” in Computer Vision – ECCV 2018, V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss, Eds. Cham: Springer International Publishing, 2018, vol. 11208, pp. 805–822.
[20] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollar, “Microsoft COCO: Common Objects in Context,” arXiv:1405.0312 [cs], May 2014.
[21] X. Liang, K. Gong, X. Shen, and L. Lin, “Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark,” arXiv:1804.01984 [cs], Apr. 2018.
[22] B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, Jun. 2018, pp. 2704–2713.
[23] R. Krishnamoorthi, “Quantizing deep convolutional networks for efficient inference: A whitepaper,” arXiv:1806.08342 [cs, stat], Jun. 2018.
[24] E. David and N. S. Netanyahu, “DeepPainter: Painter Classification Using Deep Convolutional Autoencoders,” arXiv:1711.08763 [cs, stat], vol. 9887, pp. 20–28, 2016.
[25] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation,” arXiv:1802.02611 [cs], Aug. 2018.
[26] Z. Wojna, V. Ferrari, S. Guadarrama, N. Silberman, L.-C. Chen, A. Fathi, and J. Uijlings, “The Devil is in the Decoder: Classification, Regression and GANs,” arXiv:1707.05847 [cs], Feb. 2019.
[27] K. He, X. Zhang, S. Ren, and J. Sun, “Identity Mappings in Deep Residual Networks,” arXiv:1603.05027 [cs], Mar. 2016.
[28] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely Connected Convolutional Networks,” arXiv:1608.06993 [cs], Jan. 2018.
[29] Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, and J. Liang, “UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation,” arXiv:1912.05074 [cs, eess], Dec. 2019.
[30] V. Dumoulin and F. Visin, “A guide to convolution arithmetic for deep learning,” arXiv:1603.07285 [cs, stat], Jan. 2018.
[31] K. Gong, Y. Gao, X. Liang, X. Shen, M. Wang, and L. Lin, “Graphonomy: Universal Human Parsing via Graph Transfer Learning,” arXiv:1904.04536 [cs], Apr. 2019.
[32] X. Cai and Y.-F. Pu, “FlatteNet: A Simple Versatile Framework for Dense Pixelwise Prediction,” IEEE Access, vol. 7, pp. 179 985–179 996, 2019.
1An interesting observation in the resulting image is that large-scale unsightly checkerboard artifacts are present. It is hypothesized that such artifacts are produced by the transposed convolution or deconvolution layers in the network [14]. Improvements to the network are needed to remove such artifacts.
2The model selected is Google Coral Dev Board, a single-board pocket-sized Raspberry-Pi-like ARM64 development board computer released in early-2019. It is equipped with a low powered version of Google’s patented [15] neural network accelerator ASIC chip [16] with on-chip parameter cache branded as Tensor Processing Unit (TPU) called the Edge TPU, which is designed to execute multiply-accumulate (MAC) operations of unsigned 8-bit integers at a high speed for inference of models with floating-point parameters quantized to integers. Models undergo graph transformation and quantization with Tensorflow Lite post-training quantization utility functions, and then are converted with a proprietary tool edgetpu_compiler with binary provided by Google to be run on the Edge TPU. Note that the accumulator is more than 8-bit wide to support convolution and other operations.
An alternative model is NVIDIA Jetson Nano [17] which supports 16-bit floating point operations on its CUDA cores but network models with 32-bit floating point parameters still have to undergo conversion to run on the embedded system, such as with TensorRT SDK for Tensorflow models. It has a cost and build similar to Google Coral Dev Board.
Other hardware solutions offered by less well-known brand names are also available [18].
3Note that quantized models are not only for embedded systems and can be run on the CPU of a desktop computer without a GPU as well, and an 8-bit integer quantized model may be able to perform nearly as well as 32-bit floating point models that are 4 times larger while being more light-weight [22]. Quantization reduces numeric precision of individual parameters and hence reduces representation capacity of models overall, and is therefore more suitable for large models [22, 23] with a relatively high number of parameters, say, more than 10 million.
4Add operation results in a residual connection. A 1 × 1 convolution of of high-dimensional feature maps and low-dimensional feature maps concatenated results in a linear combination, and hence can also been regarded as a residual connection.
5In the deepest encoder layer the depth of 20 × 20 features maps is not increased from 512 to 1024 since a depth increase greatly increases total parameter count without providing a substantial improvement on segmentation results for our application. For instance, a 1024-to-1024-channel feature mapping with a 3 × 3 kernel requires 1024 × 3 × 3 × 1024 + 1024 ≈ 9.44 million parameters, a 32% increase in parameters for a network with 30 million parameters.
7As an interesting note, the aspect ratios of the drawing area of the drawing tablet 6.3∕3.9 = 1.615 and the aspect ratio of
the images used in the fashion editing network 512∕320 = 8∕5 = 1.6 are both approximately equal to the golden ratio
(1 + 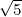 )∕2 ≈ 1.618.
)∕2 ≈ 1.618.