Video surveillance of large facilities such as airport usually requires a set of cameras for
ensuring a complete coverage of the scene. Tracking human in such scenes requires the
integration of video cues acquired from a set of cameras as the targets usually walk through
a large area. A major task of multiple-camera surveillance system is to reliably track a
person moving across cameras in the environment.
Most of the automatic surveillance approaches [1-6] require overlapping field of views
(FOVs) for tracking targets across multiple cameras. Jain and Wakimoto [1] used calibrated
cameras and an environmental model to obtain 3D location of a person. Cai and Aggarwal
[2], used multiple calibrated cameras for surveillance. Geometric and intensity features
were used to track the objects in multiple views. Collins et al. [3] developed a system
consisting of multiple calibrated cameras and a site model. They used region correlation
and location on the 3D site model for tracking. Bayesian Networks were used by
Dockstader and Tekalp [4] for tracking and occlusion reasoning across cameras with
overlapping views. Lee et al. [5] proposed an approach for tracking in cameras with
overlapping FOV’s that does not require calibration. The camera calibration information
was recovered by matching motion trajectories obtained from different views and plane
homographies were computed from the most frequent matches. Khan et al. [6] used field of
view (FOV) line constraints for tracking in cameras with overlapping views.
However, cameras with overlapping FOVs under large area coverage is usually not a
practically valid assumption. In addition, scene models or calibrated cameras are not
always available in many real environments, since the cameras usually need re-calibration
after PTZ actions, and assuring up-to-date calibration of a large network of cameras
requires significant maintenance effort.
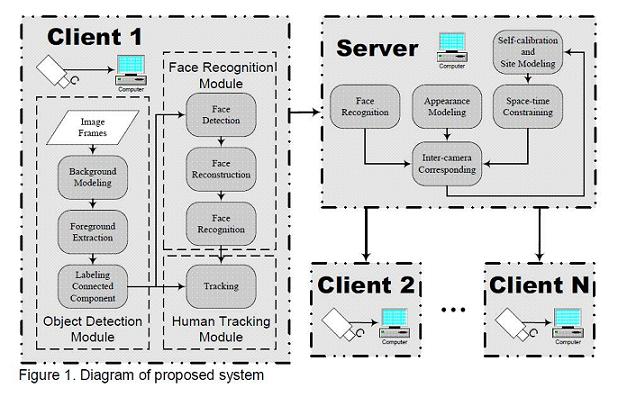
As a result, we are motivated to propose a framework to locate and track people using
uncalibrated cameras which can have overlapping and/or non-overlapping FOVs, as
illustrated in Figure 1. Client-server architecture [7] is used to implement our approaches.
At the single camera level, a client program is attached to each camera to track [8-14] all
the targets in its FOV. Face recognition results will help to handle severely occluded targets,
which most of the existing tracking systems fail to track reliably. To enhance performance of
face recognition, a face reconstruction method [15-17] is utilized to transform human face
from arbitrary pose back to a frontal one, which most of the face recognition algorithms
would have assumed. And then, the server utilizes face recognition result as well as human
appearance and space-time cue to build stronger correspondence for all of the tracked
targets. Space-time constraints can be derived within a training period by self-calibration
and scene modeling procedure.