Deep Learning Based Salient Object Detection
Guanbin Li Yizhou Yu
The University of Hong Kong
List of Papers
1. Guanbin Li and Yizhou Yu, Deep
Contrast Learning for Salient Object Detection, IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), Las Vegas, June 2016. [BibTex] (paper)
2. Guanbin
Li and Yizhou Yu, Visual
Saliency Detection Based on Multiscale Deep CNN Features, IEEE Transactions
on Image Processing (TIP), Vol 25, No 11, pp.5012-5024, 2016. (paper)
3. Guanbin Li and Yizhou Yu, Visual
Saliency Based on Multiscale Deep Features, IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), Boston, June 2015. [BibTex] (paper | supplemental)
Our HKU-IS Dataset
The HKU-IS dataset can be downloaded from Google Drive or Baidu Cloud. Please cite our CVPR 2015 paper if you use this dataset.
Deep Contrast Learning for
Salient Object Detection
1. Abstract
Salient object
detection has recently witnessed substantial progress due to powerful features
extracted using deep convolutional neural networks (CNNs). However, existing CNN-based
methods operate at the patch level instead of the pixel level. Resulting
saliency maps are typically blurry, especially near the boundary of salient
objects. Furthermore, image patches are treated as independent samples even
when they are overlapping, giving rise to significant redundancy in computation
and storage. In this paper, we propose an end-to-end deep contrast network to
overcome the aforementioned limitations. Our deep network consists of two
complementary components, a pixel-level fully convolutional stream and a
segment-wise spatial pooling stream. The first stream directly produces a
saliency map with pixel-level accuracy from an input image. The second stream
extracts segment-wise features very efficiently, and better models saliency
discontinuities along object boundaries. Finally, a fully connected CRF model
can be optionally incorporated to improve spatial coherence and contour localization
in the fused result from these two streams. Experimental results demonstrate
that our deep model significantly improves the state of the art.
2. Architecture

Two streams of our deep
contrast network
3.
Results
![]()

Visual comparison of saliency maps
generated from state-of-the-art methods, including our DCL and DCL+.
The ground truth (GT) is shown in the last column. DCL+ consistently
produces saliency maps closest to the ground truth.
4. Quantitative
Comparison
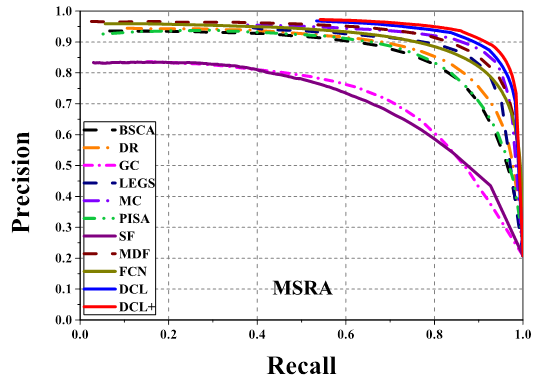
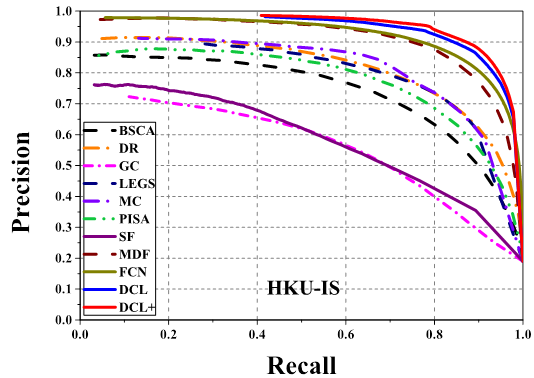
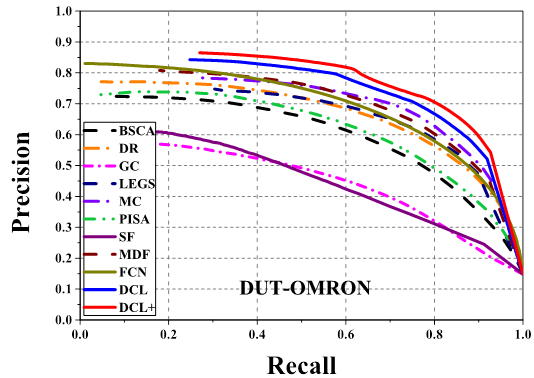
Comparison of precision-recall curves of 11
saliency detection methods on 3 datasets. Our MDF, DCL and DCL+ (DCL
with CRF) consistently outperform other methods across all the testing
datasets.
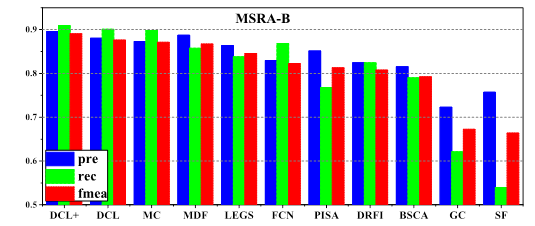
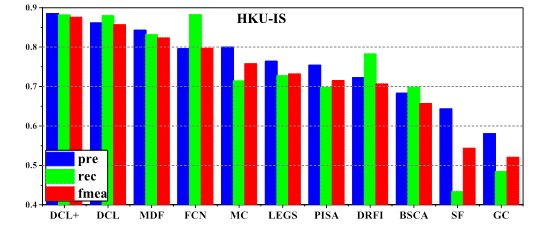
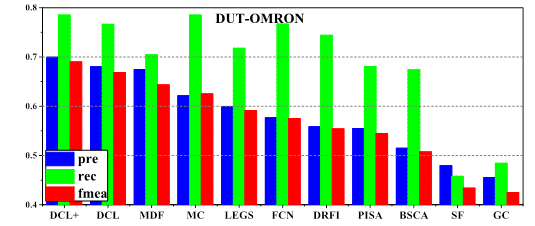
Comparison of precision, recall and F-measure
(computed using a per-image adaptive threshold) among 11 different methods on 3
datasets.
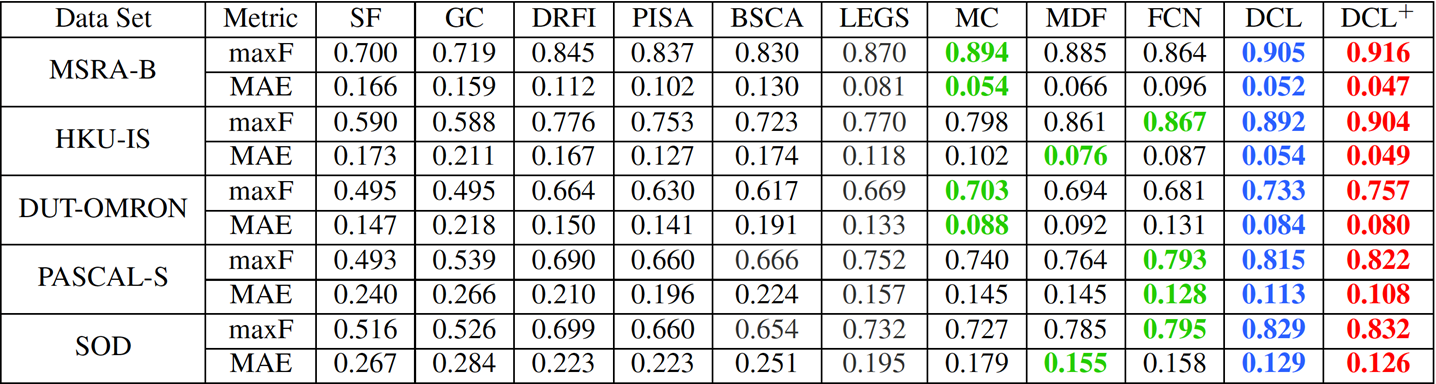
Comparison of quantitative results
including maximum F-measure (larger is better) and MAE (smaller is better). The
best three results are shown in red, blue, and green , respectively.
5. Downloads
(1) The trained model and
the test code for DCL saliency can be downloaded from google drive or Baidu Yun.
(2) Saliency
maps of our approach on 6 benchmark data sets can be download here.
Visual Saliency Detection
Based on Multiscale Deep CNN Features
1. Abstract
Visual saliency is a fundamental problem in
both cognitive and computational sciences, including computer vision. In this
paper, we discover that a high-quality visual saliency model can be learned
from multiscale features extracted using deep convolutional neural networks
(CNNs), which have had many successes in visual recognition tasks. For learning
such saliency models, we introduce a neural network architecture, which has
fully connected layers on top of CNNs responsible for feature extraction at
three different scales. The penultimate layer of our neural network has been
confirmed to be a discriminative high-level feature vector for saliency
detection, which we call deep contrast feature. To generate a more robust
feature, we integrate handcrafted low-level features with our deep contrast feature.
To promote further research and evaluation of visual saliency models, we also
construct a new large database of 4447 challenging images and their pixelwise saliency annotations. Experimental results
demonstrate that our proposed method is capable of achieving state-of-the-art
performance on all public benchmarks, improving the F-measure by 6.12% and
10.0% respectively on the DUT-OMRON dataset and our new dataset (HKU-IS), and
lowering the mean absolute error by 9% and 35.3% respectively on these two
datasets.
2. Architecture
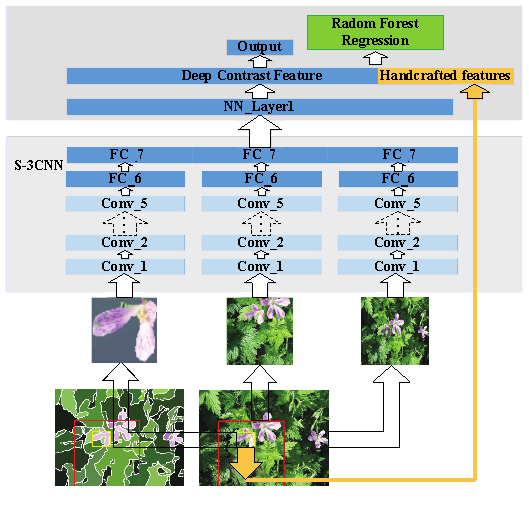
The architecture of Multiscale Deep CNN Features
3. Results
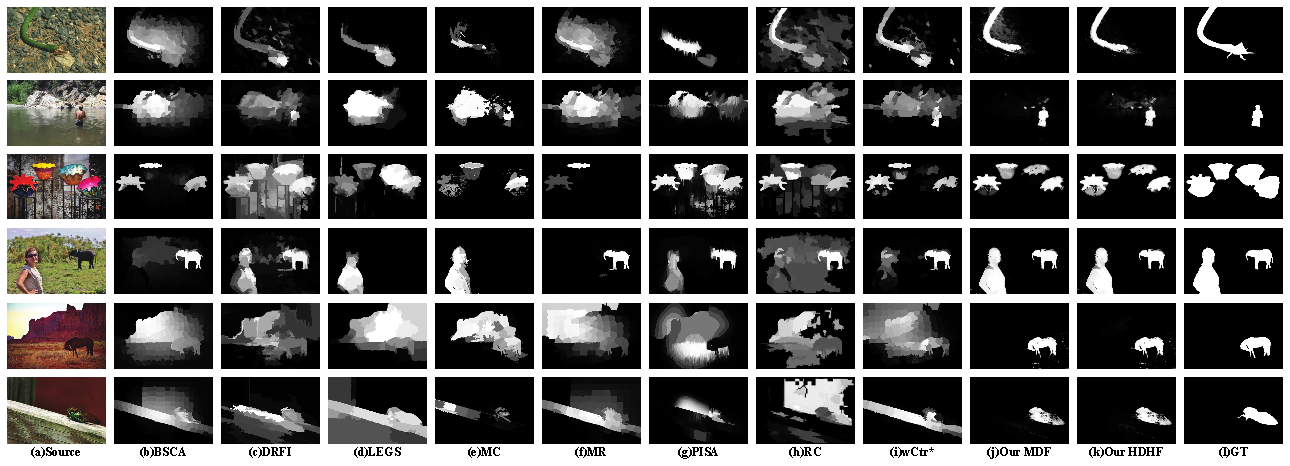
Visual
comparison of saliency maps generated from 10 state-of-the-art methods,
including our two models MDF and HDHF. The ground truth (GT) is shown in the
last column. MDF and HDHF consistently produce saliency maps closest to the
ground truth.
4. Quantitative
Comparison
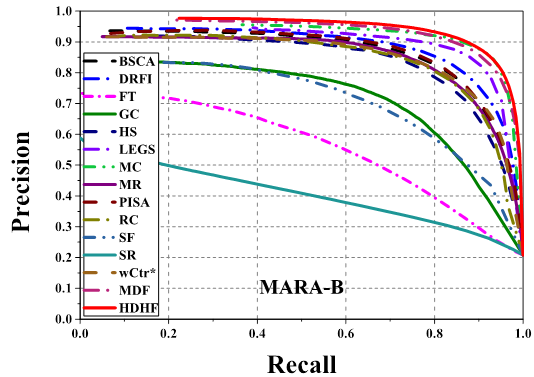
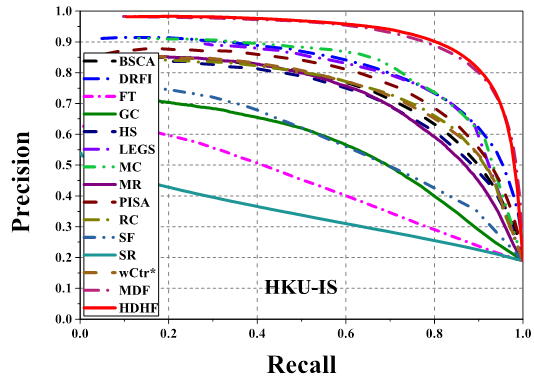
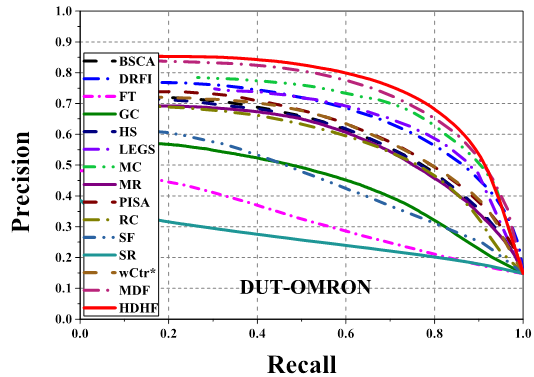
Comparison of precision-recall curves of 15 saliency
detection methods on 3 datasets. Our MDF and HDHF based models consistently
outperform other methods across all the testing datasets.
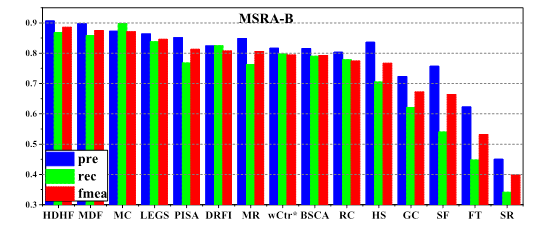
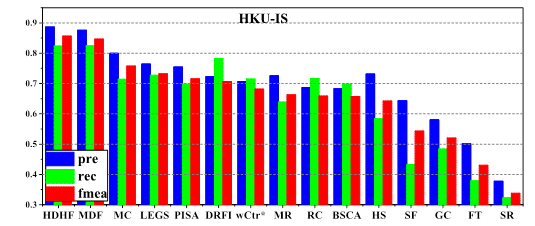
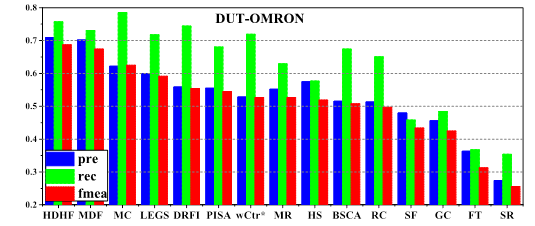
Comparison of precision, recall and F-measure
(computed using a per-image adaptive threshold) among 15 different methods on 3
datasets.

Comparison of quantitative results
including AUC (larger is better), maximum F-measure (larger is better) and MAE
(smaller is better). The best three results are shown in red , blue , and green color, respectively.
5. Downloads
(1) The trained model and test code for HDHF saliency
(TIP2016) will be released soon.
(2) To download the trained model and test code
for MDF saliency (cvpr 2015), please click here.
(3) Saliency maps of our approach on 9 benchmark
data sets can be download here. Including MSRA_B(test part), HKU-IS(test part), ICOSEG, SED1, SED2, SOD, Pascal-s, Dut-Omron, ECSSD.