The lack of the central unifying model in parallel computation as compared to the unique von Neumann model in the field of sequential computation has resulted in a long debate of selecting the representative model(s) for parallel computation. Consequently, there exist enormous number of models for parallel computation. Some of them look different, but were shown to be quantitatively equivalent [14]. Some of them look similar, but they could be completely different. In general, models have tended towards undesirable extremes. On the one hand, they are of highly theoretical qualities but be unrealistic or difficult to map onto real machines. At the other extreme, models may be too machine-oriented or complex which limit their long-term usage and portability.
Bear in mind that the definition of the model is "simply an abstract view of a system or a part of a system, obtained by removing details in order to allow one to discover and work with the basic principles" [43]. On the other hand, the complexity of designing and analyzing parallel systems requires that models be used at various levels of abstraction that are highly related to the application characteristics. Strictly speaking, it is hard to make a head-to-head comparison on models as they may involve different levels of abstraction. As our quest for a performance model is to have effective exploitation of commodity clusters for high-performance computation, so we focus our exposition of models that are based on the same architectural foundation as compared to our communication model, as well as targeting to a similar programming abstraction as we are.
It is the first to be called as bridging model [105]. Essentially,
it agrees with the generic architectural model described above, but
requires an extension that provides efficient global synchronization
on all processors. The performance of the BSP-style program can be
characterized by three parameters: p, L and g,
where p stands for the number of processors; L is the
cost of global synchronization in unit of time step; and g
corresponds to network throughput in terms of the ratio between the
number of local computational operations performed per second by all
processors, to the total number of data words delivered per second
by the router. A parallel algorithm is expressed in BSP model as a
sequence of parallel supersteps. Each superstep consists of a sequence
of local computation steps plus any message exchanges, followed by
a global synchronization. The cost of a single superstep phase is
represented by the formula ![]() , where w is the maximum
cost of the local computation on each processor, and h is the
maximum number of packets both sent and received by any processor.
The cost of the parallel algorithm is just the sum of each individual
superstep cost that comprising the algorithm.
, where w is the maximum
cost of the local computation on each processor, and h is the
maximum number of packets both sent and received by any processor.
The cost of the parallel algorithm is just the sum of each individual
superstep cost that comprising the algorithm.
Although BSP model does not explicitly stress on data locality, the gh parameter shows us how the importance of data distribution (locality) in influencing performance. Furthermore, the gh parameter implicitly captures the contention issue but inadequately, as in reality, g may be affected under congestion condition. One important performance feature it has missed out is the communication cost related to the message size, as it does not distinguish between a message of length kb and k messages of length b, but in reality, this could be a significant factor to the performance prediction and analysis. Another limitation of this model is the restricted framework - supersteps, as some parallel applications cannot fit into this programming structure, e.g. task-parallel model. The global synchronization operation between supersteps would impose a stringent requirement on the cluster communication system. This is because almost all commodity clusters are not coupled with hardware synchronization primitive, any realization of the global synchronization has to be done by software approach, which means it would contend with normal data communications. Thus, this becomes a costly overhead, especially this operation appears once in each superstep.
The LogP model [30] tends to be more empirical and network-oriented. Its includes four parameters to characterize the system: L, o, g and P, where P stands for the number of processors involved; o represents the software overhead associated with the transmission/reception of message; L is the upper bound on the hardware delay in transmitting a fixed but small size message between two endpoints; and g is the minimal time interval between consecutive messaging events at a processor, which corresponds to the network throughput available to the processor. By simply exposes these architectural parameters, we can directly derive the performance/cost when using it to analyze parallel algorithms.
An interesting concept of LogP model is the idea of finite capacity
of the network, such that no more than certain amount of messages
(
![]() ) can be in transit from
any processor or to any processor at any time. And any attempts to
exceed the limit will stall the processor. However, the model does
not provide any clear idea on how to quantify, avoid and take advantage
of this information in algorithm design. Similarly, LogP model does
not address on the issue of message size, even the worst is the assumption
of all messages are of ``small'' size; however, this has been
addressed on their follow-up study [31].
) can be in transit from
any processor or to any processor at any time. And any attempts to
exceed the limit will stall the processor. However, the model does
not provide any clear idea on how to quantify, avoid and take advantage
of this information in algorithm design. Similarly, LogP model does
not address on the issue of message size, even the worst is the assumption
of all messages are of ``small'' size; however, this has been
addressed on their follow-up study [31].
Despite of the shortcoming, this model is the pioneer model that breaks the synchrony of parallel execution as oppose to the PRAM model [37], even though it is not the first to do so. Consequently, other studies tried to extend its capabilities to support more constructive features. For examples, LogGP model [4] augments the LogP model with a linear model for long messages; LoGPC model [67] further extends the LogGP model to include contention analysis using queuing model on the k-ary n-cubes network; LogPQ model [103] augments the LogP model on the stalling issue of the network constraint by adding buffer queues in the communication lines.
The Postal model [8] is similar to LogP model with the
exception of more abstractly expressing the network. The system is
characterized by two parameters: n and ![]() , where n stands
for the number of processors and
, where n stands
for the number of processors and ![]() represents the communication
latency. The communication latency
represents the communication
latency. The communication latency ![]() is expressed as
a ratio between total time spent in transmitting the message from
sender to receiver with the time spent by the sender in initiating
the transfer. This ratio captures both the software and hardware costs,
and effectively reduces the dimension of analysis. Similarly, to simplify
the analysis, this model sacrifices the performance accuracy by neglecting
the importance of message size over communication latency. Therefore,
their cost models are better for asymptotic analysis than for prediction,
when porting the resulting algorithm to a particular platform, significant
efforts have to be made for tuning the algorithm for performance.
is expressed as
a ratio between total time spent in transmitting the message from
sender to receiver with the time spent by the sender in initiating
the transfer. This ratio captures both the software and hardware costs,
and effectively reduces the dimension of analysis. Similarly, to simplify
the analysis, this model sacrifices the performance accuracy by neglecting
the importance of message size over communication latency. Therefore,
their cost models are better for asymptotic analysis than for prediction,
when porting the resulting algorithm to a particular platform, significant
efforts have to be made for tuning the algorithm for performance.
The ![]() model [41] comes with the BSP superstep notion
and also requires to have synchronization events between supersteps.
However, on the selection of the performance parameter set, this model
adopts a tactic that lies midway between the Postal and LogP models,
which explicitly expressing the costs spent in sending and receiving
messages. The unique feature of this model is the introduction of
the congestion measures to the performance set, which measure the
congestion over communication links (
model [41] comes with the BSP superstep notion
and also requires to have synchronization events between supersteps.
However, on the selection of the performance parameter set, this model
adopts a tactic that lies midway between the Postal and LogP models,
which explicitly expressing the costs spent in sending and receiving
messages. The unique feature of this model is the introduction of
the congestion measures to the performance set, which measure the
congestion over communication links (![]() ) and congestion
at the processors (
) and congestion
at the processors (![]() ). The authors admitted that congestion
is difficult to evaluate, and they approached this problem by a rather
phenomenal way.
). The authors admitted that congestion
is difficult to evaluate, and they approached this problem by a rather
phenomenal way.
Observed that congestion depends on the total amount of data sent
between all processor pairs (cong). This model relates the
link congestion by simply estimated the cost as the per-processor
delay in routing ![]() packets across the bisection width (b),
which is shared by all processor pairs (cong), i.e.
packets across the bisection width (b),
which is shared by all processor pairs (cong), i.e.
![]() .
And the processor congestion is estimated as
.
And the processor congestion is estimated as
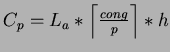 ,
where h is the average distance between processors. Their rationale
is that a message of size
,
where h is the average distance between processors. Their rationale
is that a message of size ![]() traversing a distance h links
would compete for the resources with other messages at each of the
traversing a distance h links
would compete for the resources with other messages at each of the
![]() intermediate processors, therefore is slowed down by a
factor of
intermediate processors, therefore is slowed down by a
factor of
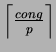 at each processor.
However, it is easy to find out that these congestion measures are
quite unrealistic. For example, the many-to-one and one-to-many communications
suffer with the same degree of link and processor congestion, which
is obviously not true in real networks.
at each processor.
However, it is easy to find out that these congestion measures are
quite unrealistic. For example, the many-to-one and one-to-many communications
suffer with the same degree of link and processor congestion, which
is obviously not true in real networks.
Motivated by the inadequacy of BSP model and the restrictive framework,
the Collective Computing Model (CCM) [86] transforms the BSP-superstep
framework to support more high-level programming model, such as MPI
and PVM. Although CCM follows the superstep terminology of the BSP
model, it waives the requirement of global synchronization between
supersteps, but combines the message exchanges and synchronization
properties into the execution of a collective communication function.
As a result, this model provides a finite set (![]() ) of
collective communication functions, which sincerely maps to the collective
operations found in MPI. Besides, it also provides a set (
) of
collective communication functions, which sincerely maps to the collective
operations found in MPI. Besides, it also provides a set (
![]() )
of cost functions for each collective function in
)
of cost functions for each collective function in ![]() ,
such that performance analysis can be made on these cost functions.
,
such that performance analysis can be made on these cost functions.
As this model is aiming for a higher level programming model, its
abstraction is more closely resembled to those common high-level message-passing
programming interfaces; therefore, it consists of a larger set of
performance parameters. As these performance parameters are directly
related to some concrete operations, quantitative analysis is therefore
possible, and the prediction quality is usually high, albeit the intricacy
of the analysis. Besides, the parameter set can be a useful tool for
evaluating message-passing software. However, this approach only contributes
minimally in designing efficient message-passing library as they cannot
provide information to guide on the design process, as they assume
that the abstract machine supports these high-level primitives. Since
this model is oriented to a high-level model, it can actually be built
atop of existing abstract models. For example, to derive the
![]() set, one can measure the performance of those collective operations
directly out of the boxes, or we can determine
set, one can measure the performance of those collective operations
directly out of the boxes, or we can determine
![]() from LogP model or from
from LogP model or from ![]() model.
model.
This model [118] is similar to the BSP model, but functionally closed to the CCM model. Under this model, a parallel execution is divided into sequence of phases. The next phase begins only after all operations in the current phase have finished, however, there are no synchronization primitive to enforce this synchrony. There are three types of phase: (1) Parallelism phase - performs process management; (2) Computation phase - executes local computation; (3) Interaction phase - executes interaction operation. There is no stringent framework in confining the sequence of phases, such that an interaction phase or another computation phase can follow a computation phase. However, different interaction operations, e.g. point-to-point communication or collective communication, may take different times. There is a general cost formula for an interaction operation:
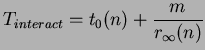
which reflects that the cost of interaction depends on the
message length (m), startup overhead (![]() ) for
an operation involves n processors, and the asymptotic bandwidth (
) for
an operation involves n processors, and the asymptotic bandwidth (
![]() )
under this communication profile. Likewise, to derive these formulae
for different interactions, the authors performed direct measurements
on the target machines [117].
)
under this communication profile. Likewise, to derive these formulae
for different interactions, the authors performed direct measurements
on the target machines [117].
![]()
|
|