Next: A.4 Microbenchmark for the
Up: A. Benchmark Methodologies
Previous: A.2 Microbenchmark for the
Contents
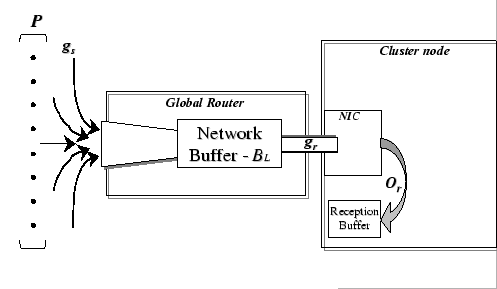
Figure A.3:
A saturated inflow pipe
|
|
This microbenchmark measures the average inter-packet arrival time
observed by a user-space process. If we can create and maintain a
steady stream of packet inflow during the testing period, this measurement
becomes a good approximation for the 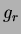 parameter. For this
microbenchmark, we simulate a saturated inflow pipe by directing a
many-to-one data flow to the target node as shown in Figure A.3.
After detecting that there are packet flooding in from the network,
the target process arbitrary selects a time point and records the
current time (
parameter. For this
microbenchmark, we simulate a saturated inflow pipe by directing a
many-to-one data flow to the target node as shown in Figure A.3.
After detecting that there are packet flooding in from the network,
the target process arbitrary selects a time point and records the
current time (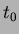 ) and arrival count (
) and arrival count (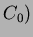 . Then
it waits for another arbitrary time period, say
. Then
it waits for another arbitrary time period, say 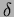 unit,
and records the current time (
unit,
and records the current time (
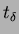 ) and arrival count
(
) and arrival count
(
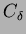 ) again. By dividing the the time gap
) again. By dividing the the time gap
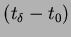 against the difference between
and
against the difference between
and 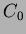 ,
we obtain an approximation for the parameter. We see
that the accuracy of this methodology improves by (1) running this
test multiple times to obtain the correct statistical distribution,
and (2) using a relatively long time duration () to
alleviate the measuring mistake.
,
we obtain an approximation for the parameter. We see
that the accuracy of this methodology improves by (1) running this
test multiple times to obtain the correct statistical distribution,
and (2) using a relatively long time duration () to
alleviate the measuring mistake.
The remaining issue of this microbenchmark falls on how can we obtain
the packet arrival count at the user-level. Here are some techniques
that serves for our need:
- Directly get the received count from the network interface card (NIC).
Most of the high-end NICs provide performance counters for diagnostic
and statistical purpose.
- Monitor and report by the interrupt handler as it is responsible for
handling incoming packets.
- The above two methods need to have support either from the hardware
or from the kernel. Otherwise, we can indirectly probe and count the
number of arrivals by the user process itself. The following pseudocode
provides a sketch on how to achieve this.
barrier ()
wait
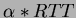 time units
time units
repeat {
msg
 async_receive
(*)
async_receive
(*)
} until (msg != NULL)
clock ()
i
1
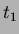 clock ()
clock ()
while (
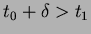 ) {
) {
msg
async_receive
(*)
if (msg != NULL)
inc i
fi
clock ()
}
Next: A.4 Microbenchmark for the
Up: A. Benchmark Methodologies
Previous: A.2 Microbenchmark for the
Contents