Methodology
Project Pipelines
This project constructs a Computer Vision model on TensorFlow, and aims at recognizing specific human hand poses from various visual sources, including images, videos and live demo.
The ultimate task, a top-down approach on hand pose recognition, will be divided into three stages, defined as followed:
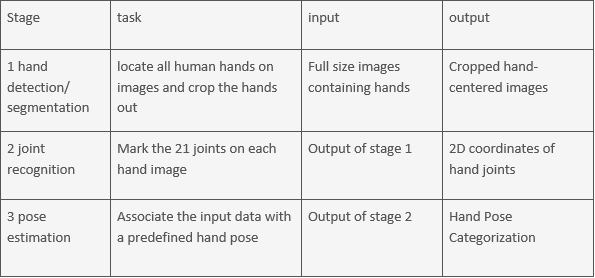 Table 1. The details responsibility of each stage, as well as input and output flows
Table 1. The details responsibility of each stage, as well as input and output flows
Data Preparation
After our literature review, we select COCO 2017[23], NYU Dataset[24] and EgoHand[25] as our training and evaluation datasets. Firstly, as mentioned in the Background section, these are the most popular datasets used in hand pose estimation, which proved to be well-diversified and comprehensive dataset with high labeling quality, both from first-person and third-person perspective. Secondly, many state-of-the-art works set baselines according to these datasets, and therefore using the same datasets provides convenient platform for horizontal comparison and evaluation.
We preprocess all the datasets into format of stage 1, 2 and 3, providing input data for each of the three stages, so that each stage can be regarded as an independent task and can be trained simultaneously.
Data augmentation can increase the amount and enhance the comprehensiveness of input data. Currently, there already exist many approaches, such as global illumination, lossy image compression, specular reflection on skin[1], as well as random crop, random rotation[2]. We will select from these methods according to the performance, and thus strengthen our network.
Network Implementation and Training
In stage 1, Hand Detection/Segmentation, we will use a pre-trained object detector and train with our hand pose datasets. At present, many existed object detection models can perform well, including RetinaNet[3], R-FCN[4] and Mask-RCNN[5], according to the leaderboard of COCO 2017 Object Detection Task[6]. Apart from model itself, the innovative ideas to train hard examples will also be taken into consideration, for example, focal loss[3] and Online Hard Example Mining[7]. We will try a series of networks and ideas to figure out one that is the most suitable for our hand detection case.
In stage 2, Joint Recognition, a series of existing networks both on hand pose and body pose will be chosen to compare the performance. Learning to Estimate 3D Hand Pose from Single RGB[8] is a good instance in this stage, while Convolutional Pose Machine[9], which initially focuses on body pose, has proved to show considerable accuracy in our preliminary attempt in adaptation to hand pose. We also look into COCO 2017 Keypoint Detection Task[10], to vertically compare with the models in the Object Detection Task[6], which provides insights to efficiently associate the first two stages altogether.
In stage 3, static image inference can be categorized in object classification, where abundant impressive models can be found. ResNet[11] and VGG[12] are both commonly used backbone network that once achieved great performance in ImageNet Competition[13]. We shall evaluate the performance of apply classification algorithm to the joints from stage 2, or apply to the hands from stage 1, and even from a concatenation of both. With regard to video inference, fewer excellent works in 2D dynamic pose have been done and thus more innovation will be involved. Our present intuition is to refer to the existing depth method based on traditional Computer Vision method[14], and then compromise with deep learning approach. Due to uncertainty on the feasibility, we might look for other approaches later on.
Evaluation and Metrics
The evaluation method we will be using on the first stage will be mean Average Precision(mAP). It calculates the .a widely accepted approach for horizontal comparisons. On the second stage, we plan to apply Object Keypoint Similarity(OKS)[15], with the formula
OKS= Σ_i [exp(-〖d_i〗^2/2s^2 )δ(v_i>0)]/Σ_i [δ(v_i>0)]
where d_iis the L2 Distance between ground truth and prediction, s^ is an object scaled factor, v indicates whether the keypoint is labelled and visible(not occluded) or not, and i denotes the index of joint. The third stage is a classification problem, and we will use softmax cross-entropy method to calculate the loss.
Apart from calculating the loss, we may also do visual judgement to justify the accuracy of model’s inference, since loss in same quantity can result from predictions with different levels of distortion.