
In many real-world problems, a substantial part of data can be added or removed. Therefore, Fully Dynamic k-Center Clustering is the best fit for its arbitrary insertion and deletion features. Fully Dynamic k-Center Clustering uses (2+e)-approximation algorithm for the k-center clustering problem with “small” amortized cost under the fully dynamic adversarial model.
Inserted data point is compared to the pre-existing clusters. If the data point is positioned within the radius of any of the k-center, it becomes part of the cluster. If it is not included, the point is classified as an unclustered point.
Deleted data point will be considered in two cases. If the point is not one of the k-centers, it can be removed in O(1) time. If the point is one of the k-centers, some points will lose their center and become unclustered points together with the clusters formulated after the deleted center’s cluster.
These points will be re-clustered by selecting uniformly random center points.


Although Python is used as a medium language for the project, most of the core functions are already available in C language. Components that can be imported via wrapper libraries, such as Cython or Pyobject, will be integrated into our system. To measure the successful integration of the components, the portions of the datasets used in Fully Dynamic k-Center Clustering (Twitter, Flickr, and Trajectories) would be used to simulate the experiment conducted in the paper.

Due to the nature of the fully dynamic k-center clustering that inserts and deletes the data points dynamically, the clusters are prone to be updated by these operations more often and refactor their structures. Therefore, clusters obtained by dynamic algorithms have a higher chance of redefining the “key” points (centers of the clusters) than those generated by static algorithms. Reassignment of these key points lead to reconstructions of the clusters, and thereby new clusters would contain different data points.
Consequently, the new clusters are, for being formulated by different members and thereby losing previous information, unstable. Hence, stability is how similar the new clusters are to the previous clusters (clusters before re-clustering), where similarity of the clusters can be measured with different metrics.

The definition of stability is not defined for the k-center clusters. Recent research paper (Information Theoretic Measures for Clusterings Comparison: Variants, Properties, Normalization and Correction for Chance) mainly discusses about methods to measure similarities between different clusters. Pair-counting, set-matching, and information theoretic measures are the classes that will be tested on our system. As mentioned in the paper, the normalized information distance (NID) would fit our purpose of comparing different clusters. Then, the stability of the clusters will be defined as the similarities calculated with the measures mentioned above.

The original Fully dynamic k-center clustering can generate unstable clusters whenever re-clustering is done after arbitrary deletion. As seen in the sample figure on the left, the algorithm loses a center at (2), then selects new uniformly random centers afterwards (3). This results in clusters(losing similarities with the original cluster) as in (4) that has different clusters which can be regarded as unstable.
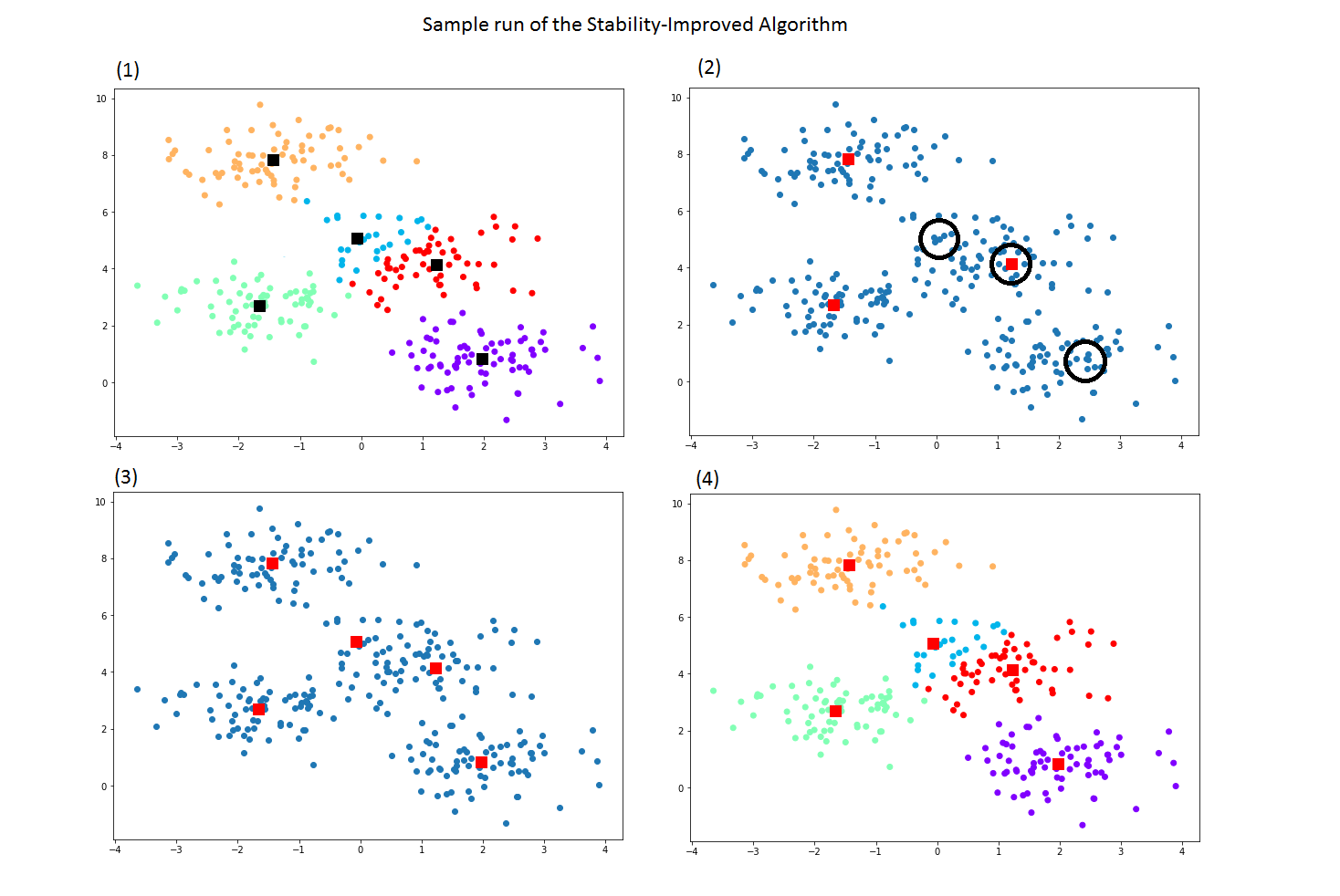
The enhanced algorithm will improve the stability with the different metrics proposed in the previous phases. As we can observe from the diagram, when deletion occurs, the algorithm takes the next most likely center in different measures(examples like pair-counting based, set-matching based measures, information theoretic measures). Rather than selecting an uniformly random center from every data points, the algorithm tries out with the stable data point that could result in making a similar cluster as before.


Referernces
Information Theoretic Measures.pdf
fully-dynamic-k-center-clustering
Our Works: