Face detection and recognition are the key technologies for a number of application
domains ranging from simple access authentications, to more complicated face
recognition-based video retrieval applications. Face detection and recognition algorithms
have been very hot research topics in the last decades and a lot of robust and practical
algorithms have been proposed and developed. Recently, these algorithms have become
very mature and reliable to the extent that they have already been put into practical
applications for use in industrial and consumer electronics. However, the great success of
these technologies rest on very restrictive assumption, in which the face of interest are all
assumed to have orientation that is passport photo alike. As a result, though it seems that
technological speaking face detection and recognition algorithms are mature, video
surveillance industry find it hard to adopt these technologies for use in practical
environment due to the fact that the human faces captured by surveillance cameras are
mostly non-passport photo alike.
In view of this, it is necessary to revisit the problems of face detection and recognition so
that they can fit better for the video surveillance types of applications such as online
identification of VIP or blacklisted customers, video retrieval based on suspect photos, etc.
Upon closer inspection within the context of video surveillance, a people captured by a
surveillance camera will be represented in the form of a flow of images, instead of a single
snapshot. The head or face orientation of a people may vary from time to time, and
therefore it poses difficulty for video surveillance and management platform to work
accurately and reliably with commodity-off-the-shelf (COTS) face recognition packages.
However, we believe we should take a different approach to address this problem by
transforming a flow of images and various face orientations, which typically be treated as
unfavorable inputs, into a form of input that is favorable for COTS face recognition
packages so that a video surveillance platform can work more reliably and accurately for
face recognition purpose. In other words, we believe that footage captured by surveillance
cameras can actually provide more informative inputs than a single snapshot for face
recognition technology to work better.
As a result, we are motivated to research into this problem and therefore the objective of
this project is to come up with a method that extracts human faces from a sequence of
frames, as well as preprocesses the face images and transform them into an image format
that is suitable for COTS face recognition packages, so that it can open up a wide range of
face recognition based application scenarios for video surveillance platforms.
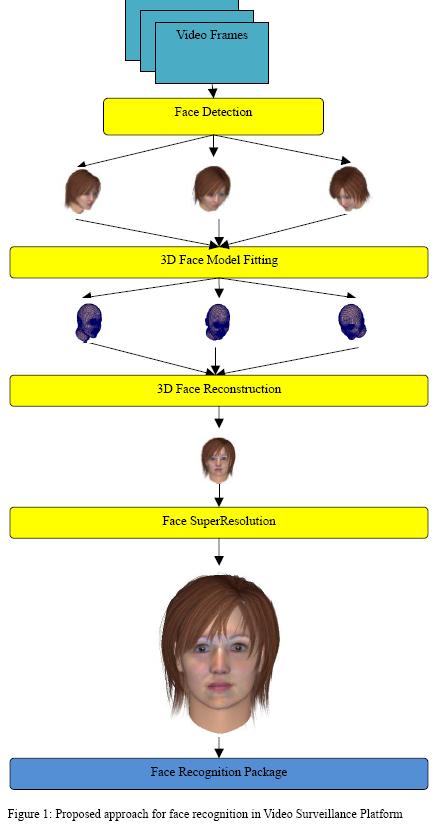
Figure 1 outline the concepts of our approach in tackling face recognition problem for
typical video images captured from surveillance cameras. In essence, we will first extract
human face from each of the image frames. Then, a 3D face model will be fitted to each of
the detected face, to allow us to estimate the face orientation as well as preparing the face
images for subsequent face reconstruction. After that, we can reconstruct and transform
each of the detected face into a format that is passport photo alike, which face recognition
package would find it easy to work with. However, as surveillance camera usually yield low
resolution image for the captured face, the reconstructed images may not have sufficient
resolution for face recognition to work reliably. To tackle this, we make use of the multiple
reconstructed face images, which represent different face orientations at different time
instants, to reconstruct higher resolution face image to boost up the accuracy and reliability
of the subsequent face recognition process.