Our experimental platform is a cluster consists of 16 standard PCs running Linux 2.0.36. Each node is equipped with a 450MHz Pentium III processor with 512 KB L2 cache and 128 MB of main memory. The interconnection network is the Fast Ethernet driven by the Directed Point communication system. Each node includes a DEC21140-based Ethernet card and connects to a Fast Ethernet Switch. Two IBM switches with different internal architectures are tested. One is the model 8275-326, which is a 24-port virtual cut-through switch, and is revealed by our microbenchmark as an input-buffered architecture. Another switch is the model 8275-416 which is a 16-port store-and-forward switch, and is revealed as an output-buffered architecture. We have implemented the above algorithms on this platform and compared their performances with the analytical formulae.
To evaluate the performance of these algorithms, model parameters
of our experimental cluster are required. Table 5.2
shows all the necessary model parameters for this cluster, which are
derived from the microbenchmark tests as described in Appendix A.
As we are assuming k-item complete exchange, we can simplify
the analysis by using a constant value for most of the parameters.
This is because all experiments are conducted with a fixed size data
packet, which is the maximum payload (1492 bytes) available to a Directed
Point packet.
|
|
[Connected by the IBM 8275-326]
 [Connected by the IBM 8275-416] [Connected by the IBM 8275-416]
|
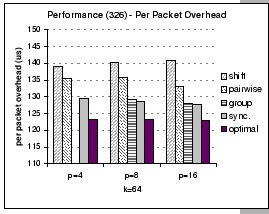
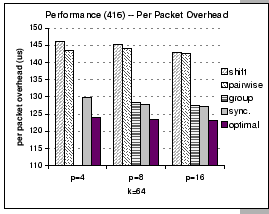
One of the features of our GBN reliable layer is the support of piggyback acknowledgement scheme. Since the communication schedule of pairwise exchange involves only a single partner in each round, we can apply optimization techniques such as piggyback and delay acknowledgement to reduce the control traffics. Based on this optimized implementation, we see that the pairwise exchange algorithm works faster than the shift exchange algorithm in all cases, although they both have the same communication complexity. This is a typical example on the tradeoff between simplicity against accuracy on the performance analysis issue. In Section 5.3, all analyses on different communication schemes are based on the assumption of the send-and-forget nature [8] of asynchronous communication. However, as the underlying network is unreliable, we have to build a reliable protocol layer to accomplish reliability. This protocol layer would induce some control traffics that inevitably interferes with the normal data flows.
|
[Connected by the IBM 8275-326]
 [Connected by the IBM 8275-416] [Connected by the IBM 8275-416]
|
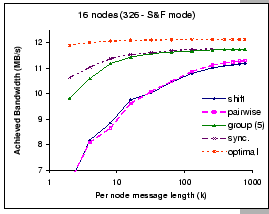
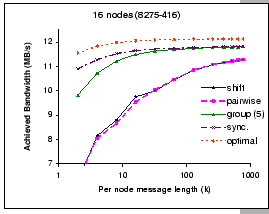
For very long messages (large k), both shift exchange and pairwise exchange are catching up with the performance of the synchronous shuffle exchange algorithm. However, for exchanging small to medium size messages in shift exchange and pairwise exchange, the waiting time incurred by each communication round cannot be masked away and results in poor performance. For example, at k=4, we observed that the achieved bandwidth of the pairwise exchange is 72% of the optimal performance, while the achieved bandwidth of the synchronous shuffle exchange reaches 92%. Furthermore, it is interested to see that the optimization techniques adopted in the pairwise exchange algorithm looks more promising on the virtual cut-through switch (IBM 8275-326) then on the store-and-forward switch (IBM 8275-416). We have repeated the same experiment on IBM 8275-326 with the cut-through mode being switched off, and we experienced the same performance pattern as reported on the IBM 8275-416 switch (in Figure 5.4).
On the other hand, the synchronous shuffle and the group shuffle exchanges perform much better even up to k=100. The synchronous shuffle scheme logically schedules all communications at the packet level in a pattern that avoids node and switch contentions. As waiting time is removed, the network links are better utilized, and we can exchange all the messages by minimal time, hence, achieved better performance. Theoretically, at the same instant, all packets arrived to different input ports are destined to different output ports according to our contention-free schedule. Therefore, this schedule should operate efficiently on any non-blocking network.
In reality, no global clock is implemented and the operations are not lock-step synchronized. The shuffle pattern of the synchronous exchange could induce head-of-line blocking on the input-buffered switch. The group shuffle exchange algorithm limits the degree of fan out and introduces minimal waiting time during the communication. As shown in Figure 5.3, it performs almost as good as the synchronous shuffle exchange algorithm even at small k.
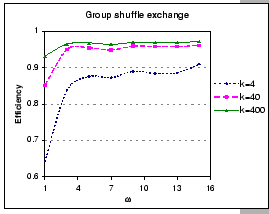
In Figure 5.5 we compare the efficiency of the group shuffle
exchange algorithms with respect to different group size ![]() for p=16 on various per node message length k=4, 40,
400. Technical speaking, with
for p=16 on various per node message length k=4, 40,
400. Technical speaking, with ![]() , the synchronous shuffle
exchange reduces to the pairwise exchange, while
, the synchronous shuffle
exchange reduces to the pairwise exchange, while
![]() corresponds to the synchronous shuffle exchange. Clearly, this figure
shows that synchronous shuffle exchange always performs the best in
all aspects. The group shuffle exchange performs considerably well
even under small
corresponds to the synchronous shuffle exchange. Clearly, this figure
shows that synchronous shuffle exchange always performs the best in
all aspects. The group shuffle exchange performs considerably well
even under small ![]() for medium to large messages as compares
to pairwise exchange.
for medium to large messages as compares
to pairwise exchange.
|
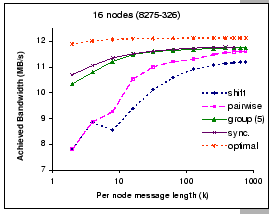
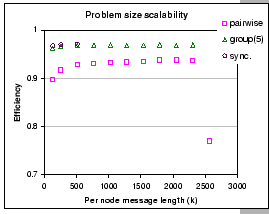
We compare the scalability of these algorithms when operated on the
input-buffered switch (IBM 8275-326) with p=16 and ![]() =5
while varying the problem size k. This test reveals the effect
of HOL problem while transmitting long messages. Figure 5.6
shows the results of this experiment. Clearly, we see that synchronous
shuffle exchange achieves the best performance, however, the performance
degraded significantly after
=5
while varying the problem size k. This test reveals the effect
of HOL problem while transmitting long messages. Figure 5.6
shows the results of this experiment. Clearly, we see that synchronous
shuffle exchange achieves the best performance, however, the performance
degraded significantly after ![]() (out of the range shown
in the graph), which corresponds to the transmission of total message
length 11 MB per node. The performance of group shuffle exchange is
only slightly worse than the synchronous shuffle exchange, and it
continues to operate at high efficiency until
(out of the range shown
in the graph), which corresponds to the transmission of total message
length 11 MB per node. The performance of group shuffle exchange is
only slightly worse than the synchronous shuffle exchange, and it
continues to operate at high efficiency until ![]() (around
49 MB per node). Lastly, we observe that the pairwise exchange continues
to work for very large message length (around 54 MB per node), but
the performance drops dramatically as the required total messaging
buffer size is approaching the machine limit, which is around 128MB.
In summary, the group shuffle exchange algorithm shows its robustness
in dealing with the HOL problem and can retain good performance for
very large message sizes.
(around
49 MB per node). Lastly, we observe that the pairwise exchange continues
to work for very large message length (around 54 MB per node), but
the performance drops dramatically as the required total messaging
buffer size is approaching the machine limit, which is around 128MB.
In summary, the group shuffle exchange algorithm shows its robustness
in dealing with the HOL problem and can retain good performance for
very large message sizes.
|
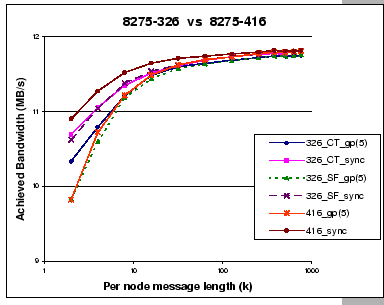
Since the complete exchange operation induces heavy network loading that stresses on the communication network severely, it could be used as a tool to evaluate the relative performance of different hardware components. Figure 5.7 shows the achieved bandwidth of the group shuffle scheme and synchronous shuffle scheme for p=16 on our two switches. Generally, both switches have the similar performance for long messages, so not much difference between the cut-through or store-and-forward modes. However, on short message exchanges, if we cannot fully utilize the network, we cannot effectively mask away the higher latency of store-and-forward switching. This is being reflected by the slower performance of the group shuffle scheme on both switches when they are working in store-and-forward mode. Furthermore, we observe that the switch internal buffering mechanism does affect the overall performance. The performance of the synchronous shuffle exchange algorithm on the output-buffered switch (IBM 8275-416) is always better than the same algorithm on the input buffered switch (IBM 8275-326) with both packet forwarding modes.
|
In Chapter 4, we observe that under heavy congestion loss, our reliable protocol may not be working efficiently due to its simplicity. For examples, we are using static window size and retransmission timer, while the sophisticated TCP/IP protocol adopts many features [93] in handling the congestion issue. Since congestion loss occurs mainly at high network load, one would think of switching back to the traditional protocol stack while we are having intensive communication scheme, such as the complete exchange operation.
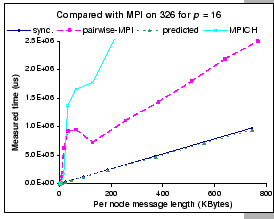
|
First, we clearly see that the original implementation of the MPI_Alltoall() function by MPICH performs extremely inefficient. This is because their implementation is based on simple non-blocking MPI_Isend() and MPI_Irecv() functions, which are issued in an uncoordinated manner. Therefore, it would subject to both node and switch contention as well as the high overhead problem that inherits from the TCP protocol stack. To avoid the node and switch contention, the ``pairwise-MPI'' carefully coordinates the communications, and achieves considerable improvement. However, our DP implementation of synchronous shuffle exchange even outperforms the ``pairwise-MPI'' implementation significantly. This shows that the traditional protocol stack has severe limitation on achieving high-speed communication. In other words, it is inadvisable to drive the high-performance communication network with the conventional communication protocols.