|
|
© Systems Research Group, Department of Computer Science, The University of Hong Kong. |
| |
|
© Systems Research Group, Department of Computer Science, The University of Hong Kong. |
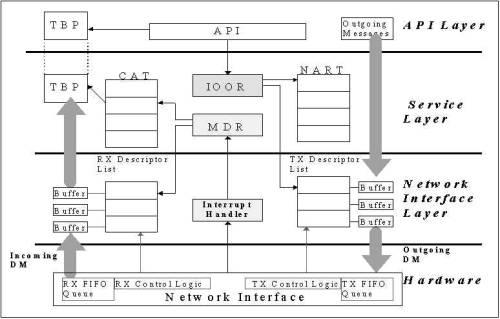
|
Main ** People ** Research ** Publications ** Facilities ** Links |
|
Directed Point: An Efficient Communication Subsystem for Cluster Computing Chun-Ming Lee, Anthony Tam, Cho-Li Wang
|
|
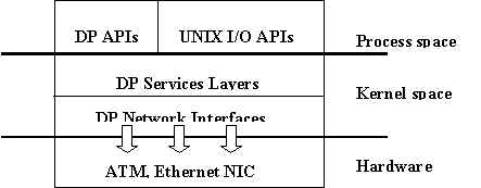
Download: Interested persons please click here to fill in the information for downloading the DP source code. Abstract: In this paper, we present a new communication subsystem, Directed Point (DP) for parallel computing in a low-cost cluster of PCs. The DP model emphasizes high abstraction level of interprocess communication in a cluster. It provides simple application programming interface with syntax and semantics similar to UNIX I/O function call, to shorten the learning period. The DP achieves low latency and high bandwidth based on (1) a efficient communication protocol Directed Messaging, that fully utilizes the data portion of packet frame; (2) efficient buffer management based on a new data structure Token Buffer Pool that reduces the memory copy overhead and exploits the cache locality; and (3) light-weight messaging calls, based on INTEL x86 call gate, that minimizes the cross-domain overhead. The implementation of DP on a Pentium (133 MHz) cluster running Linux 2.0 achieves 46.6 microseconds round-trip latency and 12.2 MB/s bandwidth under 100 Mbit/s Fast Ethernet network. The DP is a loadable kernel module. It can be easily installed or uninstalled. 1. Our Ideas: We believe that kernel-level or user-level implementation of a communication facility is not the major factor for communication performance degradation. Bad performance is due to poor architecture design, optimization techniques and implementation. Thus, kernel-level communication subsystem can also achieve low latency and high bandwidth communication. Programmability is important. It eases the application development, and allows to build higher level programming tools. We also concern how to deliver good performance on application interface level, rather than network interface level. In addition, the support of multi-process is important since cluster is a multi-user and multitasking environment. Fast communication subsystem should be able to port on different network technology. 2. DP Architecture: Only two layers implemented in kernel:
No protocol handling layer in kernel:
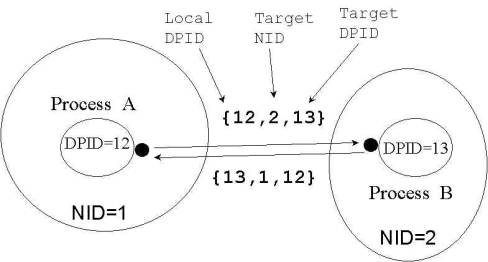
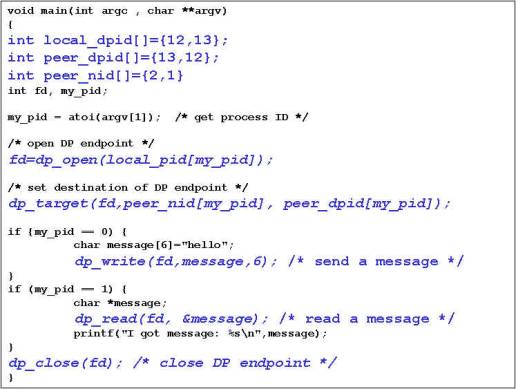
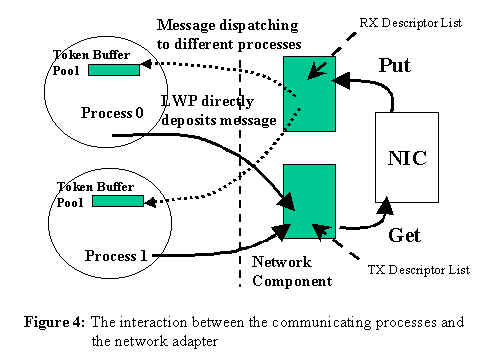
Figure 1: DP Architecture 3. Optimizing Techniques: Efficient buffer management: a. Token Buffer Pool (TBP) as receiving buffer: 1. Dedicated buffer area for receiving data 2. Shared by user process and kernel process 3. Reduces extra memory copy time,and directly use the arrived messages b. Directly deposits outgoing messages to NIC¡¦s memory: 1. Reduces intermediate buffering overhead for outgoing message Light-weight messaging calls: 1. A fast entrance to kernel 2. Avoids extra software overheads in typical system calls when switching from user mode to kernel mode. Figure 2: Transmit Process & Receive Process Overview 4. Directed Point Abstraction Model: To provide higher level of abstraction, we view the interprocess communication in a cluster as a directed graph. In the directed graph, each vertice represents a communicating process. Each process may create multiple endpoints for the identification of communication channels. A directed edge connecting two endpoints at different processes represent a uni-directional communication. The DP model can be used to describe any interprocess communication pattern in the cluster. The programmer or the parallel programming tool can easily translate the directed graph to the SPMD code. Figure 3: Directed Point Abstraction Model 5. DP Programming Interfaces: DP also provides a small set of new API which conform the semantics and syntax of UNIX I/O calls. This further makes the translation very easy. DP APIs consists of one new system call, user level function calls, lightweight message calls, and traditional UNIX I/O calls. Details of the DP API and the functions of each command is shown in Table 1. All DP I/O calls follow the syntax and semantics of the UNIX I/O calls. Similar to the file descriptor used in UNIX I/O calls to identify the target device or a file, we also use the it to abstract the communication channel. Once the connection is established, a sequence of read and write operations are performed to receive and send the data. The DP API provides handy and friendly interface for network programming. This unloads the burden of learning new API and makes it easier to be used, since the UNIX I/O calls have been widely used for developing code in the past. Table 1: The DP API Table 2: Example Program 6. Sending and Receiving: Figure 4 shows a simplified diagram for illustrating the interaction between the user processes and the network component. The network component is the Digital 21140 controller. In this example, we show two communicating processes at the user space. When a process wants to transmit the message, it simply issues either a traditional write system call or a DP lightweight messaging call dp_write( ). The process then switches from user space to kernel space. The corresponding DP I/O operation for transmission is triggered to parse the NART to find the network address based on the given NID for making the network packet frame. The network packet frame is directly deposited to the buffer pointed by the TX descriptor without intermediate buffering. Afterward, it signals the network hardware to indicate that there is message to be injected on the network. At this stage, it is on the context of calling user process or thread which is consuming its host CPU time. After the messages stored in TX descriptor, the network component takes the message and then injects it to the network without CPU interference. When a message arrives, the interrupt signal is triggered and the interrupt handler is activated. The interrupt handler calls MDR to look at the Directed Message header to identify the destination process. If it finds the process, the process¡¦s TBP is used to save the incoming message. In our implementation, the TBP is pre-allocated and locked in the physical memory. Thus, it is guarantee that the destination process will obtain the message without any delay. 7. Performance Measurement: In this section, we report the performance of DP and the comparison with other research results. Benchmark tests are designed to explore the round-trip latency and bandwidth benchmarks. We also conduct micro-benchmark tests which provide in-depth timing analysis to justify the performance of DP. 7.1 The Testing Environment
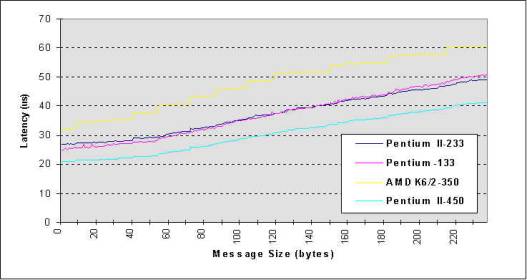
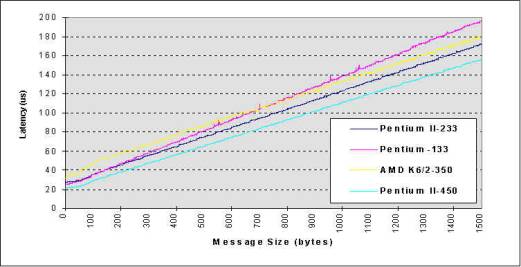
All the benchmark measurements are obtained by using software approach, and these programs are compiled by using gcc with optimization option -O2. These tests are running in multi-user mode. To have more accurate timing measurement, we construct our timing function with Pentium TSC counter that is incremented by 1 for every CPU clock cycle. Therefore, we are able to measure the execution time in very high resolution. 7.2 Bandwidth and Round-trip Latency To measure the round-trip latency, we implemented an SPMD version of Ping-Pong program using DP API. The Ping-Pong program measures the round trip time for message size from 1 byte to 1500 bytes. Timing results are obtained by measuring the average time of this message exchange operation in 1000 iterations. Figure 5: Latency: Fast Ethernet: Sending 1 byte one-way back-to-back latency: P2-450: 20.80us, P-133: 24.80us, P2-233: 26.78us, AMD K6/2-350: 31.87us Figure 6: Latency: Fast Ethernet: For Sending 1 byte to 1500 Bytes
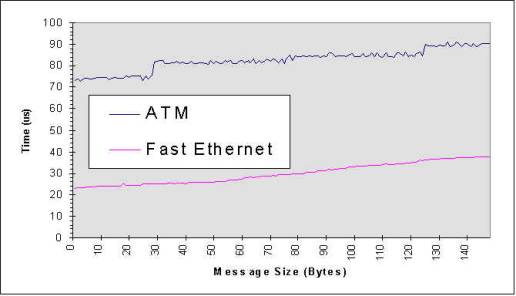
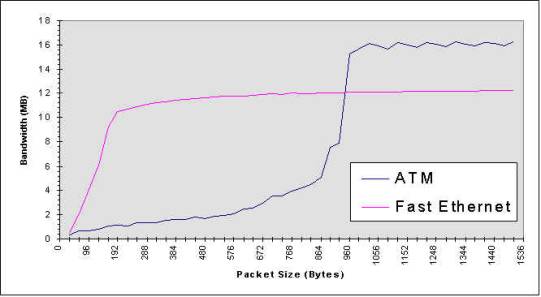
Figure 7: Latency: ATM vs. Fast Ethernet measured in Pentium 133Mhz PCs for Sending 1 byte to 1500 Bytes Figure 8: Comparison of Communication Bandwidth between ATM and Fast Ethernet using DP 8. Cost Model and Performance Analysis: To identify the overheads in communication path, we proposed a cost model which includes 5 parameters:
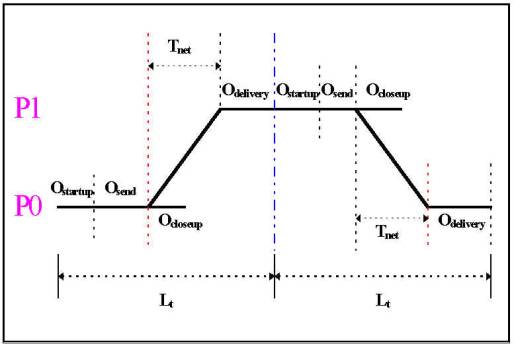
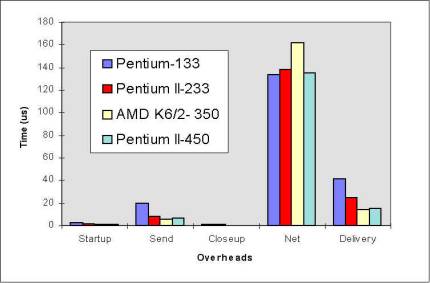
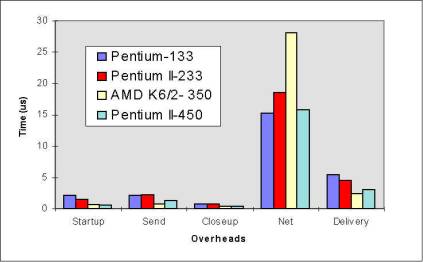
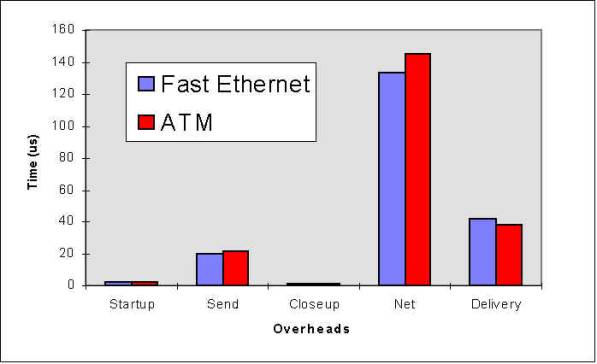
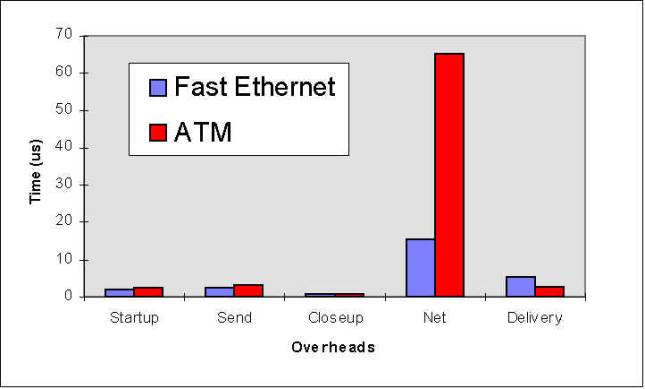
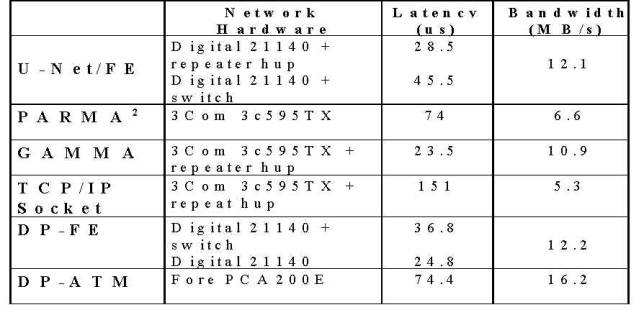
Figure 9: Breakdown of communication time between two processes P1 and P2 Figure 10: Overheads breakdown in sending 1500 bytes using Fast Ethernet Figure 11: Overheads breakdown in sending 1 bytes using Fast Ethernet Figure 12: Overhead Breakdown Comparsion Between ATM & Fast Ethernet, Measured in Pentium 133Mhz PCs: Overheads in sending 1500 bytes Figure 13: Overhead Breakdown Comparsion Between ATM & Fast Ethernet Figure 14: Performance Comparison with other implementations
|
|
Research Students: David Lee (Graduated), Raymond Wong, Anthony Tam, Wenzhang Zhu. Technical Papers:
|
|
Main ** People ** Research ** Publications ** Facilities ** Links |