About
Background
Currently, IoTs have taken the centre stage in the technology world by being one of the fastest growing markets, as it has been predicted that there will be more than 30 billion connected devices by the end of 2020. Futhermore, the amount of data which they are producing is estimated to be 100s of trillion gigabytes per year. In the near future, almost every device will be connected to the internet, ranging from sensors, vehicles, wearable electronics to other embedded systems like refrigerators. This tremendous reliance on IoT devices, generates a situation where we have to find efficient ways to communicate with them as well as charge them, specifically in the case of tiny IoT devices like an RFID or Bluetooth. One one hand, using a traditional method like battery is not a viable option for miniscule sized IoT devices. On the other hand, charging cables are not suitable, as it is not only expensive to purchase them in abundance considering each device, but also not practical for inaccessible areas. Henceforth, this project proposes the deployment of an unmanned ground vehicle in designated areas to wirelessly charge and collect data from clusters of tiny IoT devices in an operation area as shown below.
Proposal
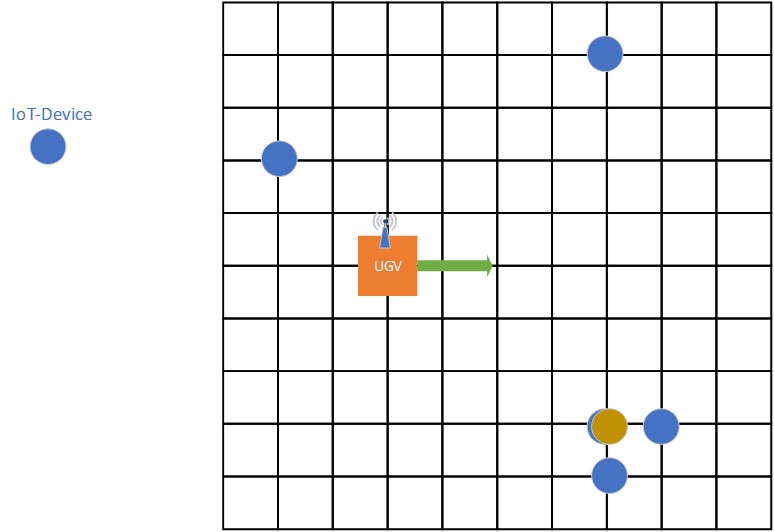
The objective is to explore different methods like Multi Integer Non-Linear Programming (as lower bound), Q-Learning and Deep Reinforcement Learning (deep Q-Learning) in order to plan the path of an unmanned ground vehicle so that it can charge the devices, meanwhile optimising both the energy consumed by it and the total path taken. Results from the above methods have been included and compared. All of the above methods are compared extensively on the basis of their efficiency and speed, and ultimately the one which gives the best result in a real world environment is chosen.
Team
Supervisor

Student
