China National Grid Project (CNGrid): Phase II (2006-2010)
HKU constructed the initial version of the HKU Grid Point with the Gideon
cluster installed in 2002 (phase I). CNGrid HKU
Grid Point was officially launched in December, 2005. It is developed
and managed by the
System Research Group (SRG) at The University of Hong
Kong (HKU). The goal of this grid point is to construct an easy-to-use,
efficient, and flexible application development platform, to support
high performance applications, such as financial computing, new drug
discovery, data mining, image rendering and animation, etc. At 2005,
HKU Grid Point consists of several large clusters including CS
Department’s Gideon300 PC Cluster and Computer Center’s
HPCPOWER
cluster, can provide over 3Tflops computing power in total. Besides supporting
high performance computing services to CNGrid project, we also involve
in the development of Hong Kong Grid and the Pearl River Delta Region
Grid (with SIAT), and are members of Pacific Rim Application and Grid
Middleware Assembly (PRAGMA) and European-based e-science project
(EGEE).
 |
|
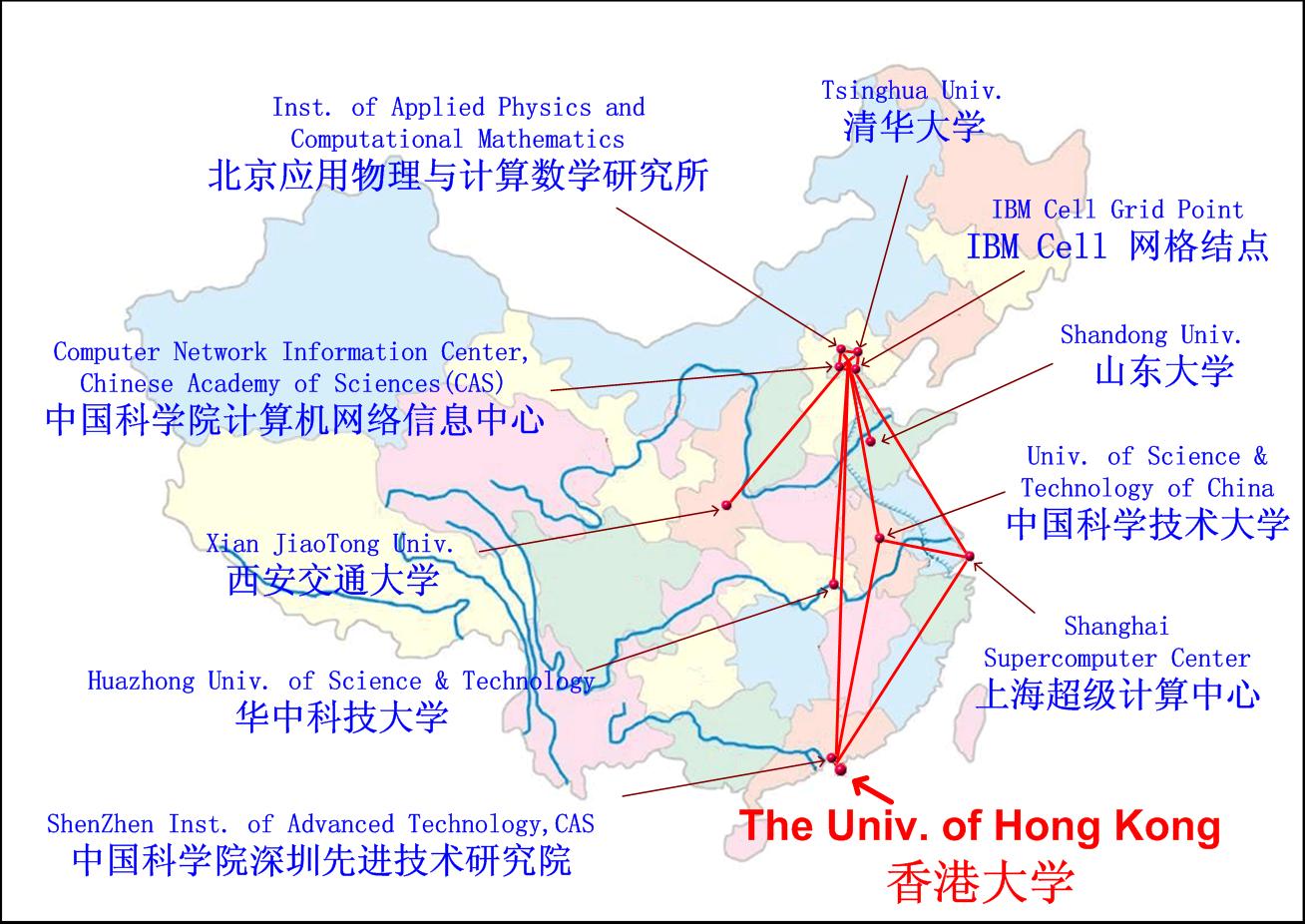
Figure 1: CNGrid Project
(phase II): Grid Node Distribution
|
The China National Grid
II (CNGrid-II) will connect
12 grid nodes across the country, including:
-
中科院计算机网络信息中心(Computer Network
Information Center, CAS)(DeepComp 7000
: 143Tflops)
-
上海超级计算中心 (Shanghai Supercomputing Center): 魔方Dawning 5000A: 230TFlops
-
清华大学 Tsinghua University (Beijing)
: 探索3号万亿次集群 (校985“三期”投资三千万建设“探索100”集群计算机, 计算性能达到104TFlops)
-
北京应用物理与计算数学研究所: 银河高性能计算机
-
中国科技大学 University of China Science and Technology (合肥Hefei, Anhui)
-
西安交通大学 Xi’an Jiaotong University:
浪潮天梭TS10000 (3.4T)
-
甘肃超算中心 曙光5000
系统峰值40Tflops
- 山东大学 Shandong U:
浪潮TS10000机群、浪潮TS20000机群
- 华中科技大学:
IBM System
p5-575 SMP
-
中国科学院深圳先进技术研究院:
曙光4000L,
1.5Tflops.
-
香港大学
Hong Kong University (Hongkong)
-
国家超算天津中心 : 天河一号A
CNGrid HKU Grid Point
The first phase of the HKU Grid Point project is implemented in early 2010. A
1920 cores of 64-bit Linux Grid point system is installed to support System
Research Group (SRG) of Department of Computer Science and Multiple Disciplines
Research Project (MDRP) for HKU researchers on Grid computing, with a total
processing power, in term of theoretical
peak performance value of 19.43 Tera-FLOPS
(and measured Rmax of 14.218 Tera-FLOPS). This system consists of latest
hardware such as Intel Nehalem Quadcore CPU, 10Gb Ethernet (10 Gb/s) switch and
4X DDR Infiniband (20 Gb/s) communication network.
The second phase of Grid Point project is expected to be completed by
early-2011. It is planned that more
computational power based on latest Intel Westmere 6-core Xeon CPUs, latest
NVIDIA Fermi Graphics processing unit (GPU) and
fastest communication based on 4X QDR Infiniband (40 Gb/s) communication
network will be implemented. It is expected that the theoretical peak
performance value of the whole system will be augmented by at least
7.62 Tera-FLOPS
after the second phase of
implementation.
This new HKU Grid Point system is supported by a high speed direct network route
between HKU network and China Science and Technology Network (CSTnet)
established at late 2009 to provide a dedicated and high-speed network
connection to China National Grid. In addition, HKU also has special research
network set-up connecting through Internet2, Trans-Eurasia Information Network
(TEIN2), Korea Research Environment Open Network (KREONET) and Taiwan Academia
Sinica Grid Computing Network (ASGCNET) directly to the research networks of US,
Japan, Singapore, Korea and Taiwan for the purpose of fast data transfer between
HKU network and other international grid networks.
Research Objectives
Part I: Building HKU Grid Point
- 扩大和升级香港大学网格结点的资源
- 实现自适应的Java计算环境:
- Integrating G-JavaMPI2 and JESSICA3
-
JESSICA:
a distributed JVM system which allows any multi-thread Java program to be
executed in a cluster without code modifications. Up to November, 2008,
JESSICA software has been downloaded over 500 times.
-
G-JavaMPI:
a Grid middleware supporting large-scale MPI-based parallel Java
computing with the support of process migration and checkpointing for
dynamic load balancing and fault-tolerance.
- Virtualization
Technique for Instant Provisioning of Grid Computing Environment
-
SLIM-VM: a new virtualization
technique that supports high-speed dissemination of virtualized Grid
computing environment among networked machines.
- 基于SLIM-VM
的网格部署方案 :
- 安装操作系统镜像,使用虚拟化,在最大的范围内实现资源的高效共享. 在一个计算结点上同时执行各种截然不同的网格计算任务
- Smart Grid Connection for Mobile Users
(普适化智能网格接入)
- 课题涵盖普适计算新环境下的移动计算中间件支持,动态自适应,情境感知,本体论映射,对等网络通信等方面
Part 2: Porting Grid Applications
- 新药发现应用网格 (中國科學院上海藥物研究所)
- Porting Tomcat on
JESSICA3.
(基于Tomcat的商业Web应用) :
- Real-time stock quotes
(实时股票报价)
- TPC-W bookstore (网上书店)
-
BetterLife
2.0 (Context-aware Recommendation System)
- Constructing HKU Campus Grid using
WAVNet
Activities
|
23/12/2011 |
十二五重大项目讨论会于2011年12月23日在中科院网络中心508会议室召开 |
|
22/01/2011 |
第三届中国国家网格学术年会 |
|
27/08/2010 |
HKU Grid Point
Inauguration Ceremony (Video)
(photos) |
|
15/08/2010 |
CNGrid GOS upgraded to version 4.0 (pdf) |
|
30/07/2010 |
Dr. C.L. Wang and Mr. Sheng Di
attended the CNGrid 2010 meeting (网格实用化推进会会议 -
内蒙古锡林浩特) (PPT) |
|
02/03/2009 |
Sheng Di presented his paper
"Gossip-based Dynamic Load Balancing in an Autonomous Desktop Grid" in
HPC Asia 2009,
Kaohsiung, Taiwan. |
|
09/2009 |
HKU's new
Gideon-II Cluster
operated in September 2009 |
|
13/12/2008 |
Dr. C.L. Wang delivered a tutorial "Grid
Technologies and Its Applications" at The 5th Workshop on Grid Technologies
and Applications (WoGTA’08),
Tainan, Taiwan. |
|
10/12/2008 |
Dr. C.L. Wang gave a keynote "Scaling Java Program on
Clusters: The Distributed JVM Approach" at
《计算机研究与发展》创刊50周年纪念
(Beijing)
|
|
25/10/2008
|
Dr. C.L. Wang gave a keynote "Scaling Java Program on
Clusters: The Distributed JVM Approach" at
GCC2008. |
|
10/01/2008 |
The HKU team
organized
The 6th
Joint Training Workshop of OMII-Europe & CNGrid (photos) |
Links for Grid Computing
Publications
-
 Sheng
Di and Cho-Li Wang, Decentralized Proactive Resource Allocation for
Maximizing Throughput of P2P Grid, to appear in Journal of Parallel and
Distributed Computing (JPDC).
Sheng
Di and Cho-Li Wang, Decentralized Proactive Resource Allocation for
Maximizing Throughput of P2P Grid, to appear in Journal of Parallel and
Distributed Computing (JPDC).
-
胡浩宇,王尹峰,王卓立,狄盛, " 云知道:基于云计算的大规模社会智能推理模型",
第三届中国国家网格学术年会, 2011年1月8日
-
王寅峰,
王卓立, 刘昊, 狄盛, "一种支持高维数据查询的并行索引机制", 第三届中国国家网格学术年会, 2011年1月8日
-
Dexter H. Hu, Yinfeng Wang,
Cho-Li Wang, "BetterLife
2.0: Large-scale Social Intelligence in Cloud Computing", The 2nd
International Conference on Cloud Computing (CloudCom 2010), Nov. 30 -
Dec. 3, 2010. (pdf)
-
Sheng Di and Cho-Li Wang,
Conflict-minimizing Dynamic Load Balancing for P2P Desktop Grid,
The 11th IEEE/ACM International Conference on Grid Computing (Grid2010)
Brussels, Belgium Oct 24 – Oct 29, 2010. (pdf)
-
Dexter
H. Hu and Cho-Li Wang, '"GPS-calibrated
Ad-hoc Localization in Urban Environment",
The 7th International Conference on Ubiquitous
Intelligence and Computing (UIC
2010), Xi'an, China, October 26-29, 2010.
-
Sheng Di and Cho-Li Wang, "Dual-phase Just-in-time Workflow Scheduling in
P2P Grid Systems", to appear in The 39th
International Conference on Parallel Processing (ICPP2010),
San Diego, California, USA, September 13-16, 2010. (pdf)
-
Ricky K.K. Ma, King Tin Lam, Cho-Li
Wang, Chenggang Zhang,
"A Stack-On-Demand Execution Model for
Elastic Computing", The 39th International Conference on
Parallel Processing (ICPP2010),
San Diego, California, USA, September 13-16, 2010. (pdf)
-
Sheng Di, Cho-Li Wang, Dexter H. Hu, "Gossip-based Dynamic Load Balancing
in an Autonomous Desktop Grid", The 10th International Conference on
High-Performance Computing in Asia-Pacific Region, (HPC
Asia 2009), March 2~5, 2009, Kaohsiung, Taiwan, pp. 85-92. (pdf)
-
King Tin Lam, Yang Luo, Cho-Li Wang,
"Adaptive Sampling-Based Profiling Techniques for Optimizing the Distributed
JVM Runtime,"
24th IEEE International Parallel and Distributed Processing Symposium
(IPDPS2010), April 19-23, 2010,
ATLANTA, USA. (pdf)
-
Yang Luo, King Tin Lam, Cho-Li Wang,
"Path-Analytic Distributed Object Prefetching", The 10th International
Symposium on Pervasive Systems, Algorithms and Networks (I-SPAN 2009), Dec.
14-16, 2009, Kao-Hsiung, Taiwan. (pdf)
-
Fan Dong, Li Zhang,
Dexter H. Hu, Cho-Li Wang,
``A
Case-based Component Selection Framework for Mobile Context-aware
Applications,'' The 7th IEEE International Symposium on Parallel and
Distributed Processing with Applications (ISPA-09),
Chengdu and Jiuzhai Valley, China, 10-12 August 2009. (pdf)
-
King Tin Lam, Cho-Li Wang, "Web Application
Server Clustering: the Distributed JVM Approach",
Handbook of Research on Scalable Computing Technologies, IGI Global,
pp.658-681 (Chapter 28), July 2009.
-
Dexter H. Hu, Fan Dong,
Cho-Li Wang,
``A
Semantic Context Management Framework on Mobile Device,'' The 6th
International Conference on Embedded Software and Systems (ICESS-09),
HangZhou, Zhejiang, China, May 25 - May 27, 2009. (pdf)
-
King Tin Lam, Yang Luo, Cho-Li Wang, A
Performance Study of Clustering Web Application Servers with Distributed
JVM, The 14th IEEE International Conference on Parallel and Distributed
Systems (ICPADS'08), Melbourne, Australia, Dec. 8-10, 2008. (pdf)
|





